
孙剑的文章
看了58同城的架构师孙剑的关于map-reduce的小文,写的很好,喜欢这种简短又能把核心点说清的文章,把核心点摘出来,以备自己快速回忆:
两篇小文很赞,一定耐心读一遍。
一览图
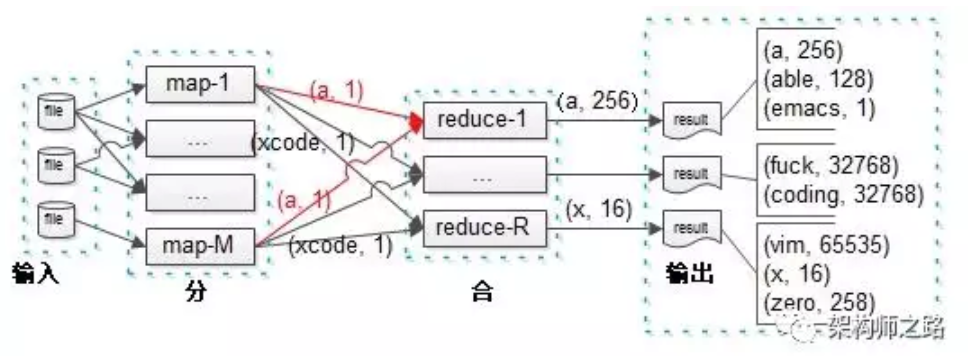
- 首先是mapper把一个文件从这台机器上load起来,mapper中就会产生这个MR中最核心的“key”,比如按照字符统计的例子里,那些字符就是核心的key
- mapper那台机器上,可能会运行个“合并函数”,用于把a的结果合并一下,没啥,就是为了提高效率
- 然后才是最重要的“分区函数”,这个分区函数运行在哪里?作者没提,我觉得应该还是在mapper的那台机器上,为什呢这么推测呢?因为,MR本质是要计算跟着数据走,能不传就不传输,那么,在没给这个计算结果找到对应的reducer之前,不能盲目的就把数据发出去,对吧?否则,发给谁,发往哪里,这个依据都没有。
- 那么就是“分区函数”,用户自己个儿写的,按照某种规则,原则啥的不说了,孙剑说的很清楚了,你不写也没事,MR会替你实现一个hash版本的
- 然后我认为,才开始传输数据,这个协调传输给那台reducer
- 一个key只会被一个reducer处理,这是一个细节,不同的reducer不可能处理同一个key
- MR系统幂等性概念很重要,不管哪个负责map的worker执行的结果,一定是不变的,产出的R个本地输出文件内容也一定是不变的 几个点还需要强调:
- 会开始在资源池中就初始化一堆的mapper和reducer,应该是有策略的,比如那些机器跑起来mapper,一台机器上跑几个mappers,reducer亦然
- 这尼玛就是一个资源池,既然是个资源池,就需要有人调度他们,那调度这事,肯定是MR系统实现的了,比如mapper应该总是问他“哥们,我这里有很多key和对应聚合出来的结果,我该发给谁啊?”,那么调度者就会跳出来,“哦!你这个这个发给这台机器的reducer,那个那个发给那台机器的reducer”。
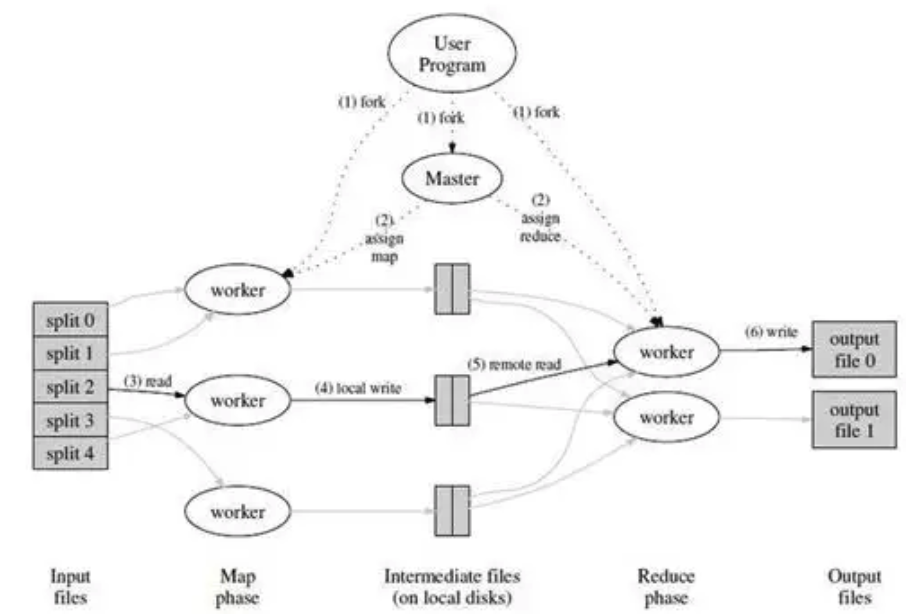
- 这图,我理解,就是发生在一台机器上的
- 开始在这个node上load起来文件,分给worker去mapper
- mapper把中间结果存到磁盘上(落盘)
- reducer再把结果合并到输出文件,等着master去进一步调度
- 这之后,肯定还会有跨机器的reducer,但是这张图,仅仅是为了讲清楚一台机器上发生的事情
我的理解,不对的话,请留言指出。
摘录
摘录一下他的一些精华字眼,您自己个儿去体会,我为何要摘录这些:
不妨假设,用户设置了M个map节点,R个reduce节点;例如:M=500,R=200
(1) 在集群中创建大量可执行实例副本(fork);
(2) 这些副本中有一个master,其他均为worker,任务的分配由master完成, M个map实例和R个reduce实例由worker完成;
(3) 将输入数据分成M份,然后被分配到map任务的worker,从其中一份读取输入数据,执行用户的map函数处理,并在本地内存生成临时数据;
(4) 本地内存临时数据,通过分区函数,被分成R份,周期性的写到本地磁盘,由master调度,传给被分配到reduce任务的worker;
(5) 负责reduce任务的worker,从远程读取多个map输出的数据,执行用户的reduce函数处理,处理结果写入输出文件;
疑问:3中说的数据,如果启动mapper worker不在数据所在的机器上怎么办?难道需要传输?我理解,应该是就这数据来生成mapper的实例更高效。不过,细想一下,也不尽然,毕竟开始任务之前,你不知道你的任务会涉及到哪些数据,看来,mapper阶段是不可避免是要传输数据的把?疑惑?
这事,我再开个脑洞,就是不传数据,而是把任务传过去,吧mapper程序传过去,传到数据所在的节点上,让此节点上的workder承接这个mapper。这里,肯定是可以通过HDFS,全局查到数据在哪里的,在哪个node上,哪个block里,然后,给这些节点把程序发过去不就得了。不知道,人家是不是这么实现的。
我前面理解中说过的“调度”,这里得到验证,就是他说的副本中有一个master,他就是任务调度节点嘛。
(1) master:单点master会存储一些元数据,监控所有map与reduce的状态,记录哪个数据要给哪个map,哪个数据要给哪个reduce,掌控全局视野,做中控;
画外音:是不是和GFS的master非常像?
(2) worker:多个worker进行业务逻辑处理,具体一个worker是用来执行map还是reduce,是由master调度的;
画外音:是不是和工作线程池非常像?这里的worker是分布在多台机器上的而已。
worker就是个干活的,他既可以看mapper的事儿,也可以干reducer的事儿。
赛赛的讲解
昨天,赛赛给我们又讲了讲,理解更深入了:
mapper - reducer
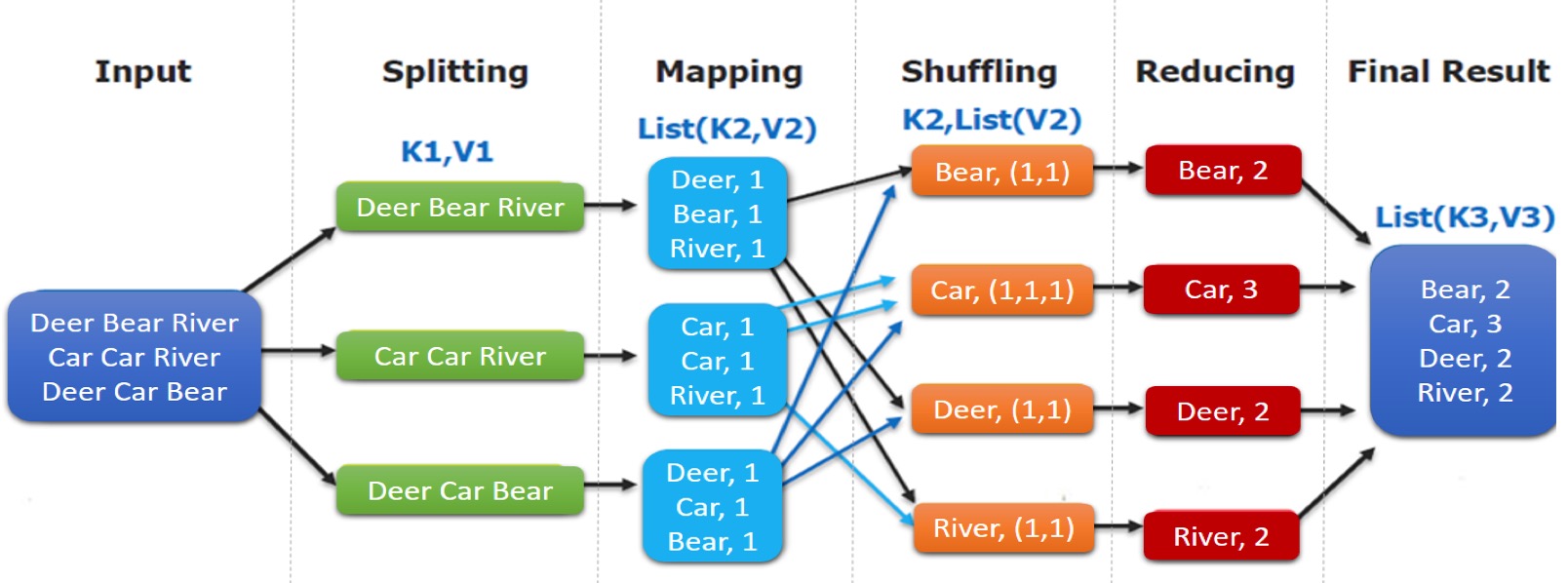
我们作为普通开发者,完成的只是mapping和reducing,最复杂的是shuffling过程(后面会讲)。
这个过程有4个参与方,如果非要细化的话:
- 最开始的分发方:他其实设计原则就是要粗暴、不考虑啥业务,也不考虑什么key映射,就是粗暴的按照128M的一个桶,把数据分配出去。(为何是128M,赛赛说是为了和HDFS的桶大小保持一致而已),他其实最重要是按照mapper数量挨个分发
- mapper方:他就是干活的人,他会按照key把这个数据发出去,可以看到,key的映射方式是框架负责的,你mapper无权决定,只要处理就好,干活就好。我问赛塞,为何不做个合并啊,把同样的key先合计一下,再emit?他回答,好问题。其实,是有这个机制的,但是是可选的。这玩意叫combinator,其本质就是个本地版的reducer而已,恩,说的好有道理。恒总说,一个词就直接吐出去,给reducer,这才是mapper的本真面目,说的也非常有道理。
map(string key,string value){ for echo word w in value: emit(w,1) } - shuffle方:这玩意最难,后面会讲,干的事也最多,他其实核心干的,就是帮着把mapper后的数据,挑一个合适的reducer,给他传过去,至于怎么传,我们后面说。
- reducer方:这个就是合并了,把某些词,注意,是有些词,但是他不知道是哪些词,拿来算个合计。至于是哪些词分配给他来统计,是由map-reduce框架来做的。他跟mapper一样,只管统计就好,然后他统计好,再发出去,至于合并后的key对应的数在哪里,我想,应该是框架直接帮着落盘到HDFS里了吧。
shuffle的细节
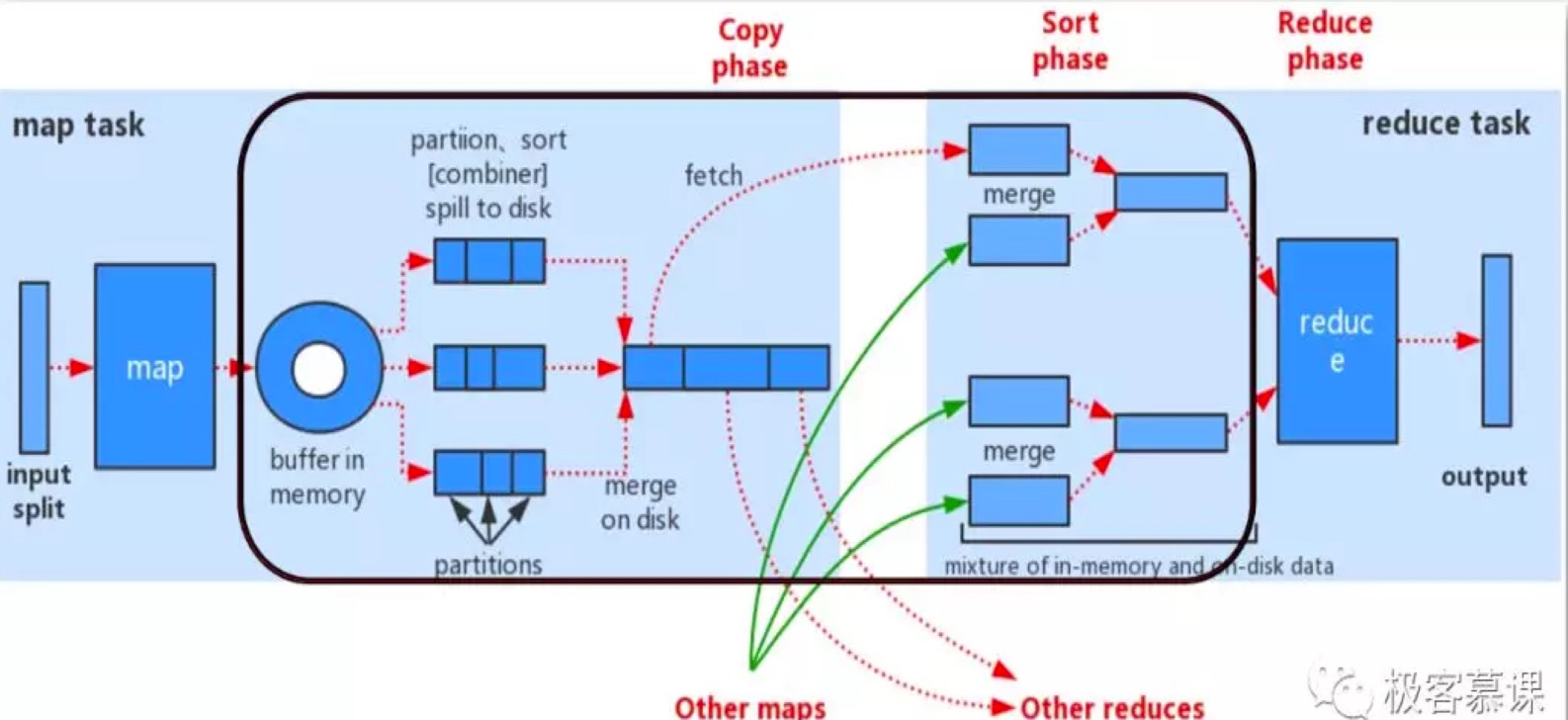
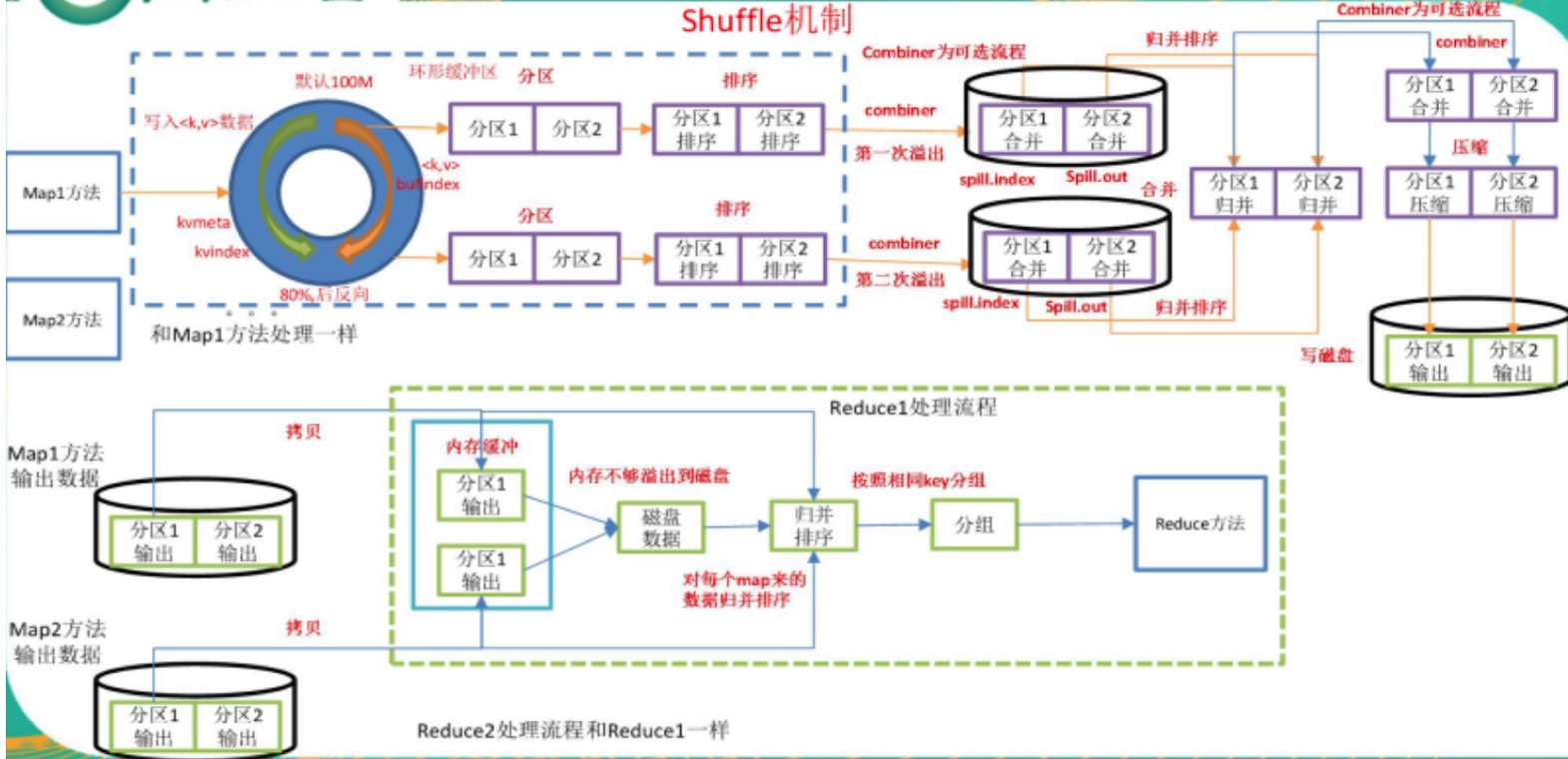
两种图差不多,都是在讲shuffle的细节。
shuffle是什么?
shuffle是个概念,是由map-reduce框架干的,主要是帮着把mapper生成的数据分发给reducer去干活。
shuffle发生在哪里?
shuffle发起,是由master节点发动的;但是,他会在mapper所在的working node上发生,也会在reducer的机器上发生。
在mapper机器上的shuffle
在mapper机器上,每个mapper算玩每个key的数据,会被写到一个所谓的partition这种,每个partition对应一个reducer,理论上,一个任务对应的reducer多少个,就应该多少个partiton队列,为了提高速度,正在内存里有个缓存队列,到80%满的时候,就把队列落盘到文件中。注意!是本地文件。
这里恒总提出是hdfs中,我们否定了他的推测,原因是,性能开销太大,他的理由也对,可以选择靠近reducer的hdfs节点存,但是开销太大了,毕竟要存3份。
然后,这些小队列,还会再合并成一个大文件,这样做是为了减少磁盘io,提高效率。合并的时候,其实,是可选地,还可以做一次combinator的。
注意,这个mapper机器上的key不是很规律分的,所有的key他都有可能收到,但是当他往和reducer数量相当的partition的时候,可不是随便写的,而是根据key在做了一个hash,保证,某些key,是按照固定规则写到某个reducer对应的partition的,为何要这样?因为后续的reducer,是被挑选好,专门处理某一类key的呀。
在reducer机器上的shuffle工作
好啦,reducer的机器开始拉取这些数据了。帅军说,这些mapper、reducer之间要保持联通,甚至无安全控制的,mapper提供一个http服务,让reducer们,点对点的去拉取mapper上的各个partition。
理论上,每个reducer服务器,都会去访问所有的mapper,因为mapper上可能保存在着所有的key们。对吧。
但是,reducer们,只会拉取自己感兴趣的key们,可是,他们怎么知道自己对哪些key感兴趣呢?别忘了,有大总管呢,大总管是谁?就是map-reducer框架,他是来分配在这些key们,该由哪些reducer负责归约的,对吧。
其他
我们还讨论了一些问题:
- map-reduce是一种思想,分治的思想
- map-reduce主要是为了解决,分布式计算的问题的,可以把各个计算任务拆分到很多机器上,但是就涉及到如何分配数据,如何归约数据,这个就是split和shuffle干的事了
- mapper之后,是落到本地磁盘上的
- reducer由大总管map-reduce框架指挥下去拉取指定的key们对应的数据
- 这是一个通用框架,google的map-reduce其实就是一个还不算太重的框架,可以考虑单独拿出来用
- 但是谷歌的map-reduce框架,是基于磁盘导致性能低下,以及只能解决离线计算,所以才会有基于内存的spark,和基于流式数据计算的storm、flink们诞生