
理解Word2Vec
CNN更接近原生的数据,图像点阵,适合直接生学, 但是文字是人类抽象过的东西,所以,要交给机器学,必须要把它原始化,所以,需要一个数据化方式把它更原始化。
TF-IDF
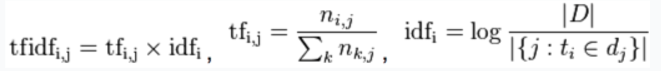
tf:一个给定的词语在该文件中出现的频率 idf:总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到 有啥用?咋用? (此处可以参考阮一峰的博客4片关于tfidf的文章:http://www.ruanyifeng.com/blog/2013/03/tf-idf.html) 1.判断搜索关键词最相关的文档:在搜索中,你的搜索词,可以被算一个tfidf,看看这个词是否在文章中的值比较高,如果高, 说明这个词在这个文章中很重要,所以,这篇文档就应该是这个搜索词。 2.抽取一篇文章的关键词:tfidf高,就说明这个词在这个文章里面重要,这样就可以排序,找出这个文章的主题词。 3.找出相似文章:一个文章的每个非停止词的tfidf组成词向量,然后算两个文章的词向量的余弦距离,得到相似对比 4.形成摘要:找出关键词,看这些词的距离相近形成簇,簇所在句子就是摘要句子
Bi-Gram/N-Gram
纬度高,很稀疏,因为Bi-Gram,就是词词间两两组合,比如1000个词,那么空间就是1000词的2排列An2(1000),忒大了,这个向量空间。
共现矩阵和SVD降维
之前的1-hot编码其实是太割裂了,其实一个词实际上背后是在各个维度上都有一个表示、一个值,而不是单纯的一个词,这种有点隐含语义的意思,词背后,可能是受他的上线文影响的,不是单纯的一个1-hot可以解决,所以引出了用一个各个维度都有值的向量来表示他的方式。其中,最好理解的是共现矩阵导出的词向量,当然还有后面的NNLM以及后续的Word2Vec向量表示,都是这个目的。
用一个词附近的其他词,来表示这个词!(这个是现代NLP最创见的想法之一!!!)
共现矩阵:
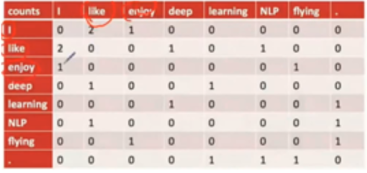
就是我和你共现次数,比如i like的一起出现了2次,这个是一个对称矩阵。
这种方式,还是稀疏、空间占用大、高纬。
所以,怎么办?降维啊,SVD降维。
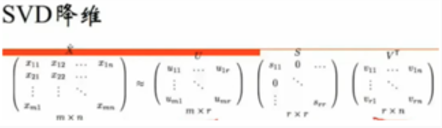
然后第一个U矩阵的,可以作为词的向量表示。(为何不用s或者v?需要再回顾下svd)
但是,svd计算量特别大,O(n^3),而且语料加入一些新词,就影响了共现,就得重新计算啊,靠。
怎么办?这就引出了NNLM:
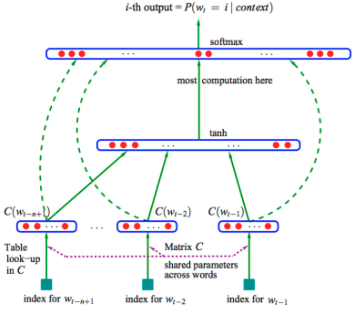
我的训练语料是文章,3个词,得到下一个词,然后滑动窗口,挪一个词,然后再滑动,又有3词,对应下一个词。滑动窗口宽度就是3
输入是1-hot的编码?!1-hot不是最稀硫的么?输入是前几个词,预测紧接着下一个词。 这个几个词的,要和一个矩阵做乘法,这个矩阵是什么?
矩阵C=(w1,w2….wn),w1-wn是词表的词,每个词是300维的,300维怎么来的?我看完全是经验,拍脑袋的。比如10万个词,300维,这个矩阵是300x10万的矩阵,然后这个矩阵随机初始化。 300x10万 乘以 10万的1hot词,得到一个300x1的向量,

就是右面乘以左面的红框。这层叫“投影层”。 感觉就是降维了,从那么高的一个维度,10万维度,变成了300维度。
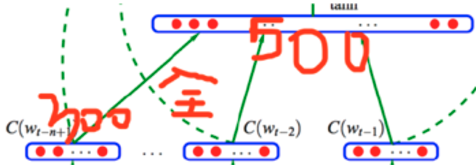
然后这3个300维度的concat拼接成900维度,然后和上面的500维度的隐含层做全连接。900x500,500怎么来的,老师说,又是拍脑袋来的。500维度啥意思,这个地方突然有些迷糊了,其实就是500个隐含层节点,每个节点和前面的900维度的那个向量做了全连接,注意我说的是向量,其实就是节点,这点上要深刻理解DNN,别糊涂。
最后,这个500维的隐含层结果,再跟做一个10万维度的结果做softmax。
300维度数据—10万x300维度—–300x1的结果—–拼接成900x1的向量—-900x500权重矩阵—-500向量—–500x10万的权重矩阵—–10万维度的softmax结果。
讲完了,我们通过交叉熵作为损失函数,反向BP算法,得到了矩阵C,矩阵C的每一列对应着每个词的词向量(也就是300x1的向量)。
这里提一句,交叉熵实际上是你最后得到的你的softmax分布,和最后第4个词(还记得么,3个词预测第四个词),两个不同分布的KL散度,可以这么理解。
然后,我们就可以引出word2vec
上面NNLM计算量太大,来,简化它!
- 去掉投影层呗
- 那10万1-hot编码,改成了直接用个300维的随机初始化向量来表示丫呢。
- 把预测位置和内容改变: CBOW(连续词袋)模型: 把前几个预测下一个(3个预测第4个),改成预测中间一个词(比如预测中间的学习“我喜欢(学习)机器学习”) Skip-Gram模型: 正好这CBOW反着,“我喜欢(学习)机器学习”,知道了中间的学习,预测“我喜欢”,“机器学习”这两边的词。
- 这4个词在NNLM是拼接在一起,那太高了维度,就1200维了,所以就不做拼接了,改成做求和,那还是300维,这样可以降低计算量。 5.把隐藏层也去掉了,靠,看,去掉了投影层,又去掉了隐含层,那不就是直接的10万维的softmax了么?!,那就是求300x10万维度的weight?(此处需要在回过头去看看softmax???)
- 也没有激活函数了,类似于NNLM中的tanh函数也省了 我靠,为何啊?老师说,这么省略,是为了计算快,把能省的都省了,就剩下线性的计算了。
- 目标函数是啥?就是把语料库滑动一遍,得到每个词的预测结果,预测的是这个词出现的概率,这样,把所有的预测概率加起来,得到一个式子,然后来优化这个式子,使其最大化。比如,预测中间的“学习”这个词出现的概率,得到这个概率,然后窗口滑动,再预测下一个“机器”的概率,然后这些结果log对数相加,得到目标函数,最大化它。
- 最后的softmax是10万维,老师说,引入huffman树的编码,搞了个层次softmax,干啥用,说是为了降维,这块没听明白??? 老师说,是把softmax的300x10万的权重,变成了这个哈夫曼树上的权重,少了很多,从N–>Log2(N)了。叶子节点有10万个。判断过程变成了从树上不停的左走右走决定,每次决定是一个LR回归,这些LR回归连乘在一起,作为目标函数。 8.1 负例采样 8中说,10万向量通过哈夫曼树降维,为何要降维?计算量大嘛,300x10万,变成了300xLog2(10w),不过,还有另外一种方法。叫负例采样。我理解是,10万维里面只要一个是正例(就对应一词嘛),其他的都不对,那么那么多个9万9千9百99个都没预测对,那么没必要都用他们来做损失函数(你看,是做损失函数的计算依据),取499个就够了吧,这样用这499个负例,1个正例,灌入到损失函数中,然后计算weight,那么怎么挑选,就通过Mikolov 这个哥们发明的负例采样方法。
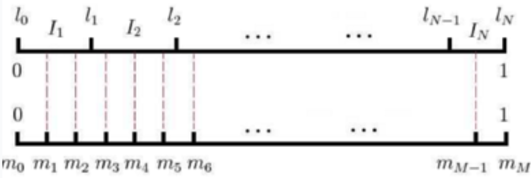
把0-1区间化成10^8等份,然后按照词频来划分这10^8份,这10万个词分别统计词频,然后这10万个词,瓜分了这10^8份,然后随机选,选中谁,就是哪个词,但是这个筛子,只是丢499次,最终和1个正样本,组成500个样本。
- word2vec的问题: 训练都是从一个上下文窗口(就是那5个大小的窗口)来训练,缺乏了整个语料的信息;还有对于多义词不好分辨,比如苹果,只有一个向量表示,但是吃的苹果和苹果公司的苹果,不是一个概念,这种就不好区别了。所以解决这些问题,相处了glove算法啥的,但是实际上大家还是爱用word2vec。
- word2vec的用途 当做一个半成品,再吐给CRF,用于NER任务啥的。
- 怎么使用:用谷歌的word2vec,或者gesim另外一个开源的
恩,好复杂,这个要一会再回来理解。 这个总结很好:

丫就是一个简化版的NNLM,所以,给他的语料不能太短,否则,这个滑动窗口根本就滑动不起来啊。
这篇文章,按照这个思路撸了一遍,很赞那: https://www.cnblogs.com/iloveai/p/word2vec.html
这篇文章,系统的再回顾一遍,里面提到了一些内容挺有用,摘抄一下 https://www.cnblogs.com/skykill/p/6785882.html
中文分词方法中,近年来随着深度学习的应用,WordEmbedding + Bi-LSTM+CRF方法逐渐成为主流 传统做法(词袋one-hot编码)主要问题的文本表示是高纬度高稀疏的,特征表达能力很弱,而且神经网络很不擅长对此类数据的处理;此外需要人工进行特征工程,成本很高。而深度学习最初在之所以图像和语音取得巨大成功,一个很重要的原因是图像和语音原始数据是连续和稠密的,有局部相关性。应用深度学习解决大规模文本分类问题最重要的是解决文本表示,再利用CNN/RNN等网络结构自动获取特征表达能力,去掉繁杂的人工特征工程,端到端的解决问题。
分布式表示(Distributed Representation)其实Hinton 最早在1986年就提出了,基本思想是将每个词表达成 n 维稠密、连续的实数向量,与之相对的one-hot encoding向量空间只有一个维度是1,其余都是0。分布式表示最大的优点是具备非常powerful的特征表达能力。
实际上word2vec学习的向量和真正语义还有差距,更多学到的是具备相似上下文的词,比如“good”“bad”相似度也很高,反而是文本分类任务输入有监督的语义能够学到更好的语义表示(我理解是给了语义标注的有监督学习)
理论和实践之间的Gap往往差异巨大,学术paper更关注的是模型架构设计的新颖性等,更重要的是新的思路;而实践最重要的是在落地场景的效果,关注的点和方法都不一样。这部分简单梳理实际做项目过程中的一点经验教训。
模型显然并不是最重要的:不能否认,好的模型设计对拿到好结果的至关重要,也更是学术关注热点。但实际使用中,模型的工作量占的时间其实相对比较少。虽然再第二部分介绍了5种CNN/RNN及其变体的模型,实际中文本分类任务单纯用CNN已经足以取得很不错的结果了,我们的实验测试RCNN对准确率提升大约1%,并不是十分的显著。最佳实践是先用TextCNN模型把整体任务效果调试到最好,再尝试改进模型。
理解你的数据:虽然应用深度学习有一个很大的优势是不再需要繁琐低效的人工特征工程,然而如果你只是把他当做一个黑盒,难免会经常怀疑人生。一定要理解你的数据,记住无论传统方法还是深度学习方法,数据 sense 始终非常重要。要重视 badcase 分析,明白你的数据是否适合,为什么对为什么错。
关注迭代质量 - 记录和分析你的每次实验:迭代速度是决定算法项目成败的关键,学过概率的同学都很容易认同。而算法项目重要的不只是迭代速度,一定要关注迭代质量。如果你没有搭建一个快速实验分析的套路,迭代速度再快也只会替你公司心疼宝贵的计算资源。建议记录每次实验,实验分析至少回答这三个问题:为什么要实验?结论是什么?下一步怎么实验?
超参调节:超参调节是各位调参工程师的日常了,推荐一篇文本分类实践的论文 A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification,里面贴了一些超参的对比实验,如果你刚开始启动文本分析任务,不妨按文章的结果设置超参,怎么最快的得到超参调节其实是一个非常重要的问题,可以读读 萧瑟的这篇文章 深度学习网络调参技巧 - 知乎专栏。
一定要用 dropout:有两种情况可以不用:数据量特别小,或者你用了更好的正则方法,比如bn。实际中我们尝试了不同参数的dropout,最好的还是0.5,所以如果你的计算资源很有限,默认0.5是一个很好的选择。
Fine-tuning 是必选的:上文聊到了,如果只是使用word2vec训练的词向量作为特征表示,我赌你一定会损失很大的效果。
未必一定要 softmax loss: 这取决与你的数据,如果你的任务是多个类别间非互斥,可以试试着训练多个二分类器,也就是把问题定义为multi lable 而非 multi class,我们调整后准确率还是增加了>1%。
类目不均衡问题:基本是一个在很多场景都验证过的结论:如果你的loss被一部分类别dominate,对总体而言大多是负向的。建议可以尝试类似 booststrap 方法调整 loss 中样本权重方式解决。
避免训练震荡:默认一定要增加随机采样因素尽可能使得数据分布iid,默认shuffle机制能使得训练结果更稳定。如果训练模型仍然很震荡,可以考虑调整学习率或 mini_batch_size。
没有收敛前不要过早的下结论:玩到最后的才是玩的最好的,特别是一些新的角度的测试,不要轻易否定,至少要等到收敛吧。