
从Word Embedding到Bert模型
这篇文档主要是受从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史启发,来梳理这条路线上涉及到的word2vec,glove,attention,transformer,elmo,gpt,birt等一系列概念。
本人也是NLP小白,把自己的学习心得记录下来,方便自己回顾,如有错误之处,请下方留言告知,也欢迎讨论留言。
这篇文章的一些摘要:
Word Embedding矩阵Q其实就是网络Onehot层到embedding层映射的网络参数矩阵。所以你看到了,使用Word Embedding等价于什么?等价于把Onehot层到embedding层的网络用预训练好的参数矩阵Q初始化了。这跟前面讲的图像领域的低层预训练过程其实是一样的,区别无非Word Embedding只能初始化第一层网络参数,再高层的参数就无能为力了。下游NLP任务在使用Word Embedding的时候也类似图像有两种做法,一种是Frozen,就是Word Embedding那层网络参数固定不动;另外一种是Fine-Tuning,就是Word Embedding这层参数使用新的训练集合训练也需要跟着训练过程更新掉。
Word Embedding头上笼罩了好几年的乌云是什么?是多义词问题。word embedding无法区分多义词的不同语义,这就是它的一个比较严重的问题。
对近义词,ELMO提供了一种简洁优雅的解决方案,ELMO是“Embedding from Language Models”,ELMO的本质思想是:我事先用语言模型学好一个单词的Word Embedding,此时多义词无法区分,不过这没关系。在我实际使用Word Embedding的时候,单词已经具备了特定的上下文了,这个时候我可以根据上下文单词的语义去调整单词的Word Embedding表示,这样经过调整后的Word Embedding更能表达在这个上下文中的具体含义,自然也就解决了多义词的问题了。
https://www.jianshu.com/p/a6bc14323d77
Bert采用和GPT完全相同的两阶段模型,首先是语言模型预训练;其次是使用Fine-Tuning模式解决下游任务。和GPT的最主要不同在于在预训练阶段采用了类似ELMO的双向语言模型,当然另外一点是语言模型的数据规模要比GPT大。
Bert本身在模型和方法角度有什么创新呢?就是论文中指出的Masked 语言模型和Next Sentence Prediction。Masked就是,随机扔掉15%的词让丫预测;NextSentence是让他预测后一句(随机找的)是不是真的是第一句的后续(因为有真实的后一句的对比)。
Bert的输入部分,也算是有些特色。它的输入部分是个线性序列,两个句子通过分隔符分割,最前面和最后增加两个标识符号。每个单词有三个embedding:位置信息embedding,这是因为NLP中单词顺序是很重要的特征,需要在这里对位置信息进行编码;单词embedding,这个就是我们之前一直提到的单词embedding;第三个是句子embedding,因为前面提到训练数据都是由两个句子构成的,那么每个句子有个句子整体的embedding项对应给每个单词。把单词对应的三个embedding叠加,就形成了Bert的输入。
$\color{red}{}$
Attention
之前的就写过一篇关于word2vec的文章,提到过attention,这里需要在复习一二:
Attentin机制的发家史
Attention机制最早是应用于图像领域的,九几年就被提出来的思想。随着谷歌大佬的一波研究鼓捣,2014年google mind团队发表的这篇论文《Recurrent Models of Visual Attention》让其开始火了起来,他们在RNN模型上使用了attention机制来进行图像分类,然后取得了很好的性能。然后就开始一发不可收拾了。。。随后Bahdanau等人在论文《Neural Machine Translation by Jointly Learning to Align and Translate》中,使用类似attention的机制在机器翻译任务上将翻译和对齐同时进行,他们的工作算是第一个将attention机制应用到NLP领域中。接着attention机制就被广泛应用在基于RNN/CNN等神经网络模型的各种NLP任务中去了,效果看样子是真的好,仿佛谁不用谁就一点都不fashion一样。2017年,google机器翻译团队发表的《Attention is all you need》中大量使用了自注意力(self-attention)机制来学习文本表示。这篇论文引起了超大的反应,本身这篇paper写的也很赞,很是让人大开眼界。因而自注意力机制也自然而然的成为了大家近期的研究热点,并在各种NLP任务上进行探索,纷纷都取得了很好的性能。
[引]
- Attentin机制
- 《Neural Machine Translation by Jointly Learning to Align and Translate》
- 《Recurrent Models of Visual Attention》
- 《Attention is all you need》
[]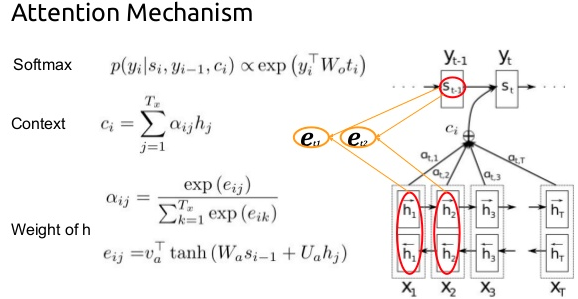
这张图里,得说明几点
- 就是attention是每一次(啥叫每一次,就是没预测一个新的$y_i$)都需要生成一次
- 怎么生成呢?
- 先是$s_{i-1}$和$h_j$搞一下,$s_{i-1}$是$y_{i-1}$的隐含层输出啊,$h_j$是encoder中的某个隐含层输出啊,呵呵,俩隐含层输出搅到一起
- 然后每个$h_j$都和这个$s_{i-1}$搞一下,然后归一化成softmax:$\alpha_{ij}$,注意一下,下标$i$ 是不变的,$i$是decoder的第几步
- 然后,用每个j的softmax值$\alpha_{ij}$,再乘以$h_j$,得到这个$\color{red}{注意力}$$c_i$
- 最后,把这个$c_i$ + $y_{i-1}$ + $s_{i-1}$,三个一搞,搞出最后的$y_i$,论文里面提到了还有一步,这里写出来,$s_i=f(s_{i-1},y_{i-1},ci)$
- 最最后,我们要的就是$y_i = p( y_i | y_1, … , y_{i-1} , s_i )$
总结一下,就是,decoder的每一步,都要全面扫描所有的输入(encoder)中的每个元素,来得到一个注意力值,参与最后的decoder结果判定。
这里要复习一下attention,主要是,接下去讨论的transformer中的attention,被作者做了一个变形,引入了K (( Key)) ,Q ((Query)),V((Value))的概念,很晕,这里把原有的attention,朴素的讲解过一遍,方便后面最对照。
Transformer
好,说transformer了,第一次是由谷歌6位大神在经典文章《Attention is all you need》提出的概念。
下面还有些中文小文,供参考:
- https://zhuanlan.zhihu.com/p/34781297
- https://www.jianshu.com/p/3f2d4bc126e6
- http://nlp.seas.harvard.edu/…/attention.html
- https://jalammar.github.io/illustrated-transformer/
- https://www.jianshu.com/p/3f2d4bc126e6
- https://jalammar.github.io/illustrated-transformer/ 陈楠推荐的一篇e文的
- http://xiaosheng.me/2018/01/13/article121/
- https://zhuanlan.zhihu.com/p/47812375 知乎小文,带代码实现 都不如这篇讲的最好:
https://kexue.fm/archives/4765
卧槽!这篇讲的真好,讲出了很多insight:
- RNN无法很好地学习到全局的结构信息,因为它本质是一个马尔科夫决策过程。
- 所谓“多头”(Multi-Head),就是只多做几次同样的事情(参数不共享),然后把结果拼接。
- 如果做阅读理解的话,Q可以是篇章的词向量序列,取K=V为问题的词向量序列,那么输出就是所谓的Aligned Question Embedding。
- 在Google的论文中,大部分的Attention都是Self Attention,即“自注意力”,或者叫内部注意力。
- 所谓Self Attention,其实就是Attention(X,X,X)Attention(X,X,X),XX就是前面说的输入序列。也就是说,在序列内部做Attention,寻找序列内部的联系。
- 它表明了内部注意力在机器翻译(甚至是一般的Seq2Seq任务)的序列编码上是相当重要的,而之前关于Seq2Seq的研究基本都只是把注意力机制用在解码端
- Self-Attention模型并不能捕捉序列的顺序!换句话说,如果将K,V按行打乱顺序(相当于句子中的词序打乱),那么Attention的结果还是一样的。这就表明了,到目前为止,Attention模型顶多是一个非常精妙的“词袋模型”而已。(什么叫打乱顺序??结果一样呢??没理解)
- Google再祭出了一招——Position Embedding,也就是“位置向量”,将每个位置编号,然后每个编号对应一个向量,通过结合位置向量和词向量,就给每个词都引入了一定的位置信息,这样Attention就可以分辨出不同位置的词了
- 结合位置向量和词向量有几个可选方案,可以把它们拼接起来作为一个新向量,也可以把位置向量定义为跟词向量一样大小,然后两者加起来。FaceBook的论文和Google论文中用的都是后者。直觉上相加会导致信息损失,似乎不可取,但Google的成果说明相加也是很好的方案。看来我理解还不够深刻。
- 无法对位置信息进行很好地建模,这是硬伤。尽管可以引入Position Embedding,但我认为这只是一个缓解方案,并没有根本解决问题。举个例子,用这种纯Attention机制训练一个文本分类模型或者是机器翻译模型,效果应该都还不错,但是用来训练一个序列标注模型(分词、实体识别等),效果就不怎么好了。那为什么在机器翻译任务上好?我觉得原因是机器翻译这个任务并不特别强调语序
视频讲解的,好像国内还没有,只有油管上有个https://www.youtube.com/watch?v=iDulhoQ2pro,B站上也是转的这个,你就不用遍大街再找了,不难,听一遍大致就明白了。
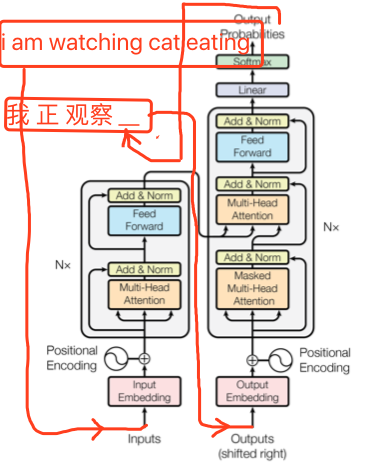
- 典型的翻译场景里,原文(英文)是左面的输入(input embedding),而翻译出来的(中文)是右面(outputs embedding)的输入
- 左面input和右面output的Multihead-Attention都是self-attention,也就是K、V、Q都是一样的,而右面的output的第二个attention的输入的V就是第一个output输出的向量了
- 我理解,输入就不变了,就是开始整句英文的输入。而输出是每次输入(好别扭,就是右侧的输入),每次是变得,即每次都是翻译出来的中文的所有的词的向量。
- 细品一下,和上面的attention的不同处。每次decoder产生新的词的时候,输入的encoder的$c_i$,是一个固定的东西了;之前的attention,每次还是变的。我理解,原因是,encoder通过positonal encoding和multi-head来充分压榨出这个句子的表示了。positional不用说了,是位置,而multi-head,则是用多个向量来表达一句话,比如8维,就相当于以8个视角来看待这句话,每个视角是不一样的,充分的挖掘这个句子的含义。
变量说明
Attention公式:$Attention(q_t,K,V) = \sum_{s=1}^m \frac{1}{Z}\exp\left(\frac{\langle q_t, k_s\rangle}{\sqrt{d_k}}\right)v_s$
每个句子都对应的是一个矩阵$X=(x1,x2,…,xt)$,$x_i$都代表着第$i$个词的词向量(行向量),维度为$d$维,故 $X\in\mathbb{R}^{n×d}$
$\boldsymbol{Q}\in\mathbb{R}^{n\times d_k}, \boldsymbol{K}\in\mathbb{R}^{m\times d_k}, \boldsymbol{V}\in\mathbb{R}^{m\times d_v}$ $d_k$都是词向量的维度,而Q中的$n$和K、V中的$m$则是对应的词的数量,比如一句话的长度。而在self-attention的话,就是输入句子的词的数量。
所以,所以,Attention输出的是,Attention层,将$n×d_k$的序列Q编码成了一个新的$n×d_v$的序列。
K/V是一样长度($m$)的,而Q是另外一个长度($n$)的,K/V你可以理解为文章,Q你可以理解为问题(阅读理解场景),然后得到了和Q长度一样长$n$的一个$d_v$维度的向量数组,就是结果($nxd_v$)。
这里面丝毫没提及参数矩阵的事情,令人费解,看了原始论文,也没提。
不过,看多头(multi-head)的时候,倒是说到了参数:
多头Head公式:$head_i = Attention(\boldsymbol{Q}W_i^Q,\boldsymbol{K}W_i^K,\boldsymbol{V}W_i^V)$
你看,参数来了:$W_i^Q\in\mathbb{R}^{d_k\times \tilde{d_k}}, W_i^K\in\mathbb{R}^{d_k\times \tilde{d_k}}, W_i^V\in\mathbb{R}^{d_v\times \tilde{d_v}}$
然后,多头把每一个(h个)attention concat到一起:
$MultiHead(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = Concat(head_1,…,head_h)$
然后contact后的这个$n ×(h×d_v)$的矩阵,还要乘以一个 $(h×d_v) x d_v$的$W$,最终得到一个$n x d_v$的向量。
所有,多头出来的结果是,最后得到一个$n ×(h×d_v)$的一个矩阵,n是Query的长度,$d_v$是Value的维度,h是多头的个数。 所以,这个时候,一个多头的参数个数是,$h \times d_k \times d_k + h \times d_k \times d_k + h \times d_v \times d_v + (h×d_v) x d_v$个参数。
加入$d_k=d_v=128,h=8$,一个attention的参数个数就是524288个参数。
看这篇
这里,attention变成了这个样子:
最左面是一个基础的attention,然后聚合起来就成了Multihead Attention了,然后这个 Multihead Attention才组成了Transformer。
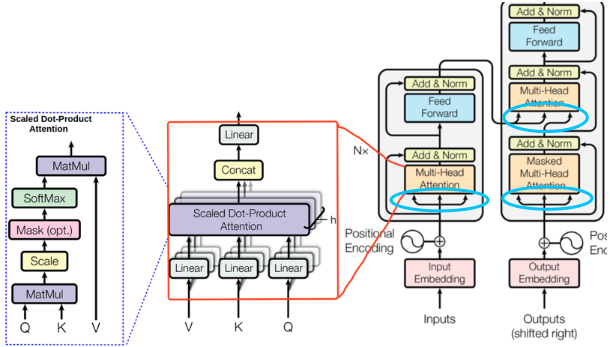
陈楠给的这篇讲Transformer的真好,虽然是e文的,讲的恨透: https://jalammar.github.io/illustrated-transformer/
先整体看看:
文中的这两张图真的很帅,可耻地盗链了:
![]()
![]()
一图,还TM的是动图,一言不合就上图,胜千言啊~~~
- 看,貌似输入算一遍之后,就再也不用了,不像之前的attention,还要不断地使用$s_{i-1}$,[
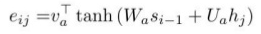 ],看,每次算注意力,还都要扯上decoder的内容。现在呢?一次算完encoder内容,形成K、V。然后就不用折腾了,以后的decoder都用这个K、V
],看,每次算注意力,还都要扯上decoder的内容。现在呢?一次算完encoder内容,形成K、V。然后就不用折腾了,以后的decoder都用这个K、V
接下来,详细地捋一遍整个过程,大量地盗版这篇文章的图了要,惭愧
1.先说清楚transformer的本质,就是一个堆叠的编码器和解码器
![]()
2.在具体点,encoder里面是个self-attention结构+前向网络,decoder是self-attention结构 + encoder-decoder-attention前向网络。
![]()
3.然后这个self-attention结构中,运算细节如下图。x1会对应三个矩阵$W^q,W^k,W^v$,相乘得到q,k,v。你看,q、k、v都是来自于x1,而x1则是单词的embeding表示。(这里我有个问题,这个单词的embeding表示可以直接用词向量么?还是需要自己通过这个网络进行训练)

4.转成张量形式,就是如下图。这个时候,要批量输入了,因为一句话会有多个词嘛。(突然那种冒出batch,那如果是batch个句子怎么办?一个词是一个512维度向量,一个句子大概有10个词,那就是100x512,是一个二维的样子了。如果再加上多个句子,就是一个立方体了,哈。那也会遇到bucket的问题的呀???脑海中浮现出多个问题,不过这些是细节,有时间再烧脑)
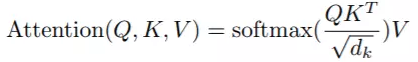


5.在回顾一下,从x输入,经过各自矩阵运算,得到k/q/v,然后k/q/v经过softmax运算后,再经过多头运算,形成8个$z_i$。最后,8个$z_i$concat,乘以一个$W^o$,最终得到一个向量z。就是这个self-transformer单元的输出。如下图:
![]()
这张图片显示了不同的多头中的每一头,对输入encoder的时候,对encoder中某个字“it”的注意力情况:
![]()
6.好,最后把encoder,decoder的堆叠形象的画出来,总览图看一下:
![]()
问题:beam search的时候,输入下一个的$y_i$应该用哪一个,是beam search出来的那个?还是概率最大的那个?
再看篇中文的,讲transformer的
这篇讲的不错,可以再过一遍https://www.jianshu.com/p/ef41302edeef
- 论文里都是6个堆叠,也就说,6个encoder,6个decoder。
这里有个特别点就是masking, masking 的作用就是防止在训练的时候 使用未来的输出的单词。 比如训练时, 第一个单词是不能参考第二个单词的生成结果的。 Masking就会把这个信息变成0, 用来保证预测位置 i 的信息只能基于比 i 小的输出。
- 这个是说,那个特殊的“masked multi-head attention”,就是只能参考之前的位置的预测的结果。
举个例子, 比如 张量(tensor)a 是一个四维矩阵,维度是[3,4,5,6], 张量 b 也是一个四维矩阵, 维度是[5,4,6,3], 那么 dot(a,b) 的维度就是 [3,4,5,5,4,3].
- 这个真心没明白,点乘不是个变标量,衡量相似度的操作么?那怎么从4层的张量变成了6层的张量了呢?不明白。。。


- 这图有点意思,先说左面的,一目了然,各种attention的关注点。self-attention其实就是用自己和自己进行对焦,前面举的那个例子,“it”指代的就是自己所在这句话的哪个词,我理解,就是对这句话进行了深度解析。而encoder-decoder attention,最右侧很明显就是encoder得到的浓缩代表了输入句子的浓缩向量。
- 右图呢?是说,用CNN只能在扫到窗口内的词,而用attention可以照顾到全句,就是这个意思。
多头注意力机制很棒啊。 首先each head, 是可以并行计算的, 然后每个head 都有自己对应的weight, 实现不同的线性转换, 这样每个head 也就有了自己特别的表达信息。 所以Fig. 5 里的每个连接 是用彩色表示的 - 多头,可以并行算,这个很好,就喜欢并行的东西。这样,encoder的可以并行算,decoder也可以并行算,再也不用像rnn那样,必须等着前面的算完了,才能算下一个。不过,这里好像算下一个,还是得等前一个算完了才可以,我是说在decoder的时候(我的笑容戛然而止)

- 这图也太帅了把,一共6层,很明显,上面3层是3个encoder层,下面是3个decoder层
- encoder过程中,第一层画的不好,感觉每个词的处理有先后顺序似得,其实是没有的,并行的,比如英译汉,”i love beijing”,3个词是同事灌给第一个encoder的
- 最终第三个(堆叠在最上面的)encoder输出一个 1 x 512 x 句子长度 x batch-size 的一个张量(妈蛋,真像吴恩达说的,搞清每个输出的维度真不是容易事)
- 然后decoder过程中,encoder就不工作了,每层decoder都用这个最上层encoder的输出了
- decoder每次要吃之前decode出来的所有内容,还是英译汉,要翻译最后一个词“北京”,那decoder输入就是“我 爱”两个词(是概率分布,还是确定的词,可能还要搅和beam search,这块有点晕???)
SOTA(state-of-the-art)预训练模型
ELMo、ULMFiT、GPT,三个过度模型,虽然是过度模型,但也都是SOTA啊,因为要迫不及待去研究BERT,回头再来补课…
参考:https://zhuanlan.zhihu.com/p/42618178
BERT
参考
- 原始论文
- 谷歌BERT模型深度解析
- 最强NLP论文到底强在哪里?
- 如何评价 BERT 模型?
- BERT相关论文、文章和代码资源汇总
- 2018年最强自然语言模型 Google BERT 资源汇总
- 如何应用 BERT
- 谷歌BERT模型fine-tune终极实践教程
- 两行代码玩转 Google BERT 句向量词向量
- 一些基于BERT的实践
问题:
- 在BERT使用attention来预测被扣掉的词,这个过程中的QKV是啥?