
1、概述
网上文章,很多了,他们讲的我都不想细讲了,可以参考最后的参考文档,我只会谈谈我的一些理解。
是的,奇怪的废话少说,直奔主题吧….
2、论文解读
先给个下载地址:https://arxiv.org/pdf/1704.03155.pdf
说啥pipeline,说白了就是2步就文本检测这事儿搞定,要是你搞过CTPN,就知道丫多繁琐。这两步是啥?
- 一个网络,砰地一声,就检测出每个点是否是文本点,以及他到围绕他的那个框的4个距离
- 再来一个local aware NMS 完事!
2、1 网络结构
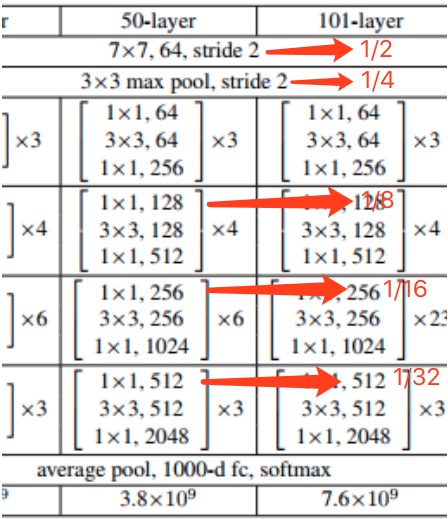

这图很多人都讲过了,他们见过的东东,我就不提了,补充我自己的理解:
- argman大神的代码子用的是resnet V50,无所谓啦,只要这个pretrain网络可以吐出来conv4,conv3,conv2,conv1 4个feature map,而且是每个都是上一个的1/2就成.
- 左面的图就是resnet50,可以观察一下哪里让图像变小的,箭头的地方就是变小的地方,有的是pool,大部分是靠stride=2的卷积,而且这个卷积都在第一个block,后面组内重复的block是stride=1了
- 有个细节,右图中的f4,大小是图像的1/4,而不是原图大小,这个细节很重要,影响代码实现
- 从最后uppooling+contact后的合成的最后的那个大图中,实际上是512x512x32的那个feature map,到最后的score map/geometry map/angel map,就是绿色=>蓝色的这块是咋做的呢?答案是,用的是一个1x1的卷积实现的
F_score = slim.conv2d(g[3],1,1, activation_fn=tf.nn.sigmoid, normalizer_fn=None) geo_map = slim.conv2d(g[3], 4, 1, activation_fn=tf.nn.sigmoid, normalizer_fn=None) * FLAGS.text_scale angle_map = (slim.conv2d(g[3], 1, 1, activation_fn=tf.nn.sigmoid, normalizer_fn=None) - 0.5) * np.pi/2 # angle is between [-45, 45]
2、2 样本数据
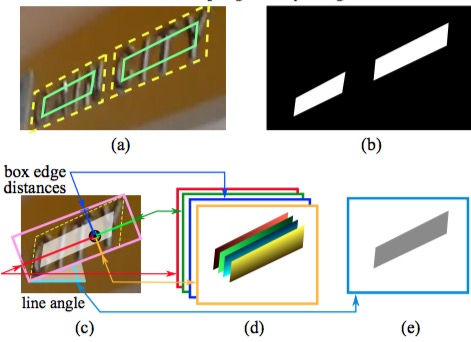
再说说这图,这图是啥啊?是告诉你样本咋做。
- 左上那个黄框是GT(标注),但是真正用的正样本,是绿框,往里缩进了1/3,你问为何,我也不知道,我估计是让这些点更靠里,更可信吧。而且,这样预测的4个值(上下左右)可能才都大小差不多。
- 最后我们的样本是啥,是5张图,对,6张图,跟输入的数据,原图,大小一样,都是1通道的
- b就是一个score map的例子,很直观,但是geometry map就不一样了,每个像素点代表的值是啥呢?是他们到对应位置的长度。啥意思?比如geometry map中的第一张,就是每个像素,到他对应的那个文本框的上边的距离,对,这个geometry map图像中的每个值,都是这个像素距离他对应的文本框上沿的距离。所以,geometry图,4张,分别应该叫“上沿图、下沿图、左沿图、右沿图”,这个理解了,角度图也应该理解。合计,你算算,正好是6张图。
2、3 到底预测了啥
有个特别浅显的问题?就是,到底EAST预测了啥?
其实,他就是预测了每个像素,对,每个像素,他是不是文本框的点。如果是,那么他到包裹他的文本框的上下左右的距离是多少。注意,这个文本框是一个带角度倾斜的矩形框。
既然每个点都预测一个框出来,那么就会出现矛盾。比如我和你本是挨着的点,可是我预测的到框的距离,和你预测的框的距离,有差异。(本来大家挨的很近,不应该相差太多),这个时候,需要用NMS算法来合并,可是点太多了,主要是NMS搞起来,效率太低了,所以论文里提了个LANMS算法。
最后通过不同点的得到的框,通过LANMS合并后,得到的最后的框,就是我们要的文本检测的框们。
3、代码解读
说说代码吧,我们的代码在这里,for argman的,传送门
我们补充了大量的注释,把我们的理解都写到了里面,应该对你阅读代码很有帮助。但是,有些细节,还是要在这里特殊说明一下。
3、1 样本准备
样本准备是第一步,也是代码里写的复杂的,idar.py::generator是入口。
https://github.com/zyh8306/EAST/blob/master/utils/icdar.py
- shrink_poly函数,是论文中说的,将文本区缩小1/3,是为了让正样本置信度更高
if tag:cv2.fillPoly(training_mask, poly.astype(np.int32)[np.newaxis, :, :], 0),这句话是处理那么模糊的框,认为他不是文本框,毕竟,模糊的框,我们也就不勉强了- crop_area方法很诡异,到底是干嘛的呢?其实,就是把框
crop_area方法
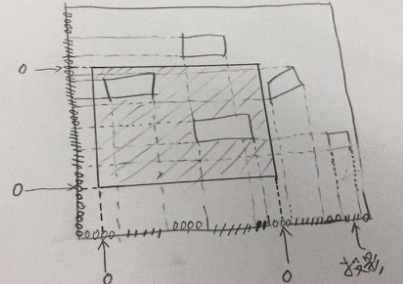
- 把文本框往x轴做投影,再往y轴做投影,投影落到的地方为1,没有落到的位置为0。
- 然后在0的地方采样,x轴采2个,y轴采2个,然后用这4个点,可以切出一张子图来
- 这张子图,包含一定数量的文本框,并且,不会把一个文本框切成两半
为何要这样做?
我理解,是为了,做样本增强,这样一张图,其实可以被随机分割好多次,相当于多出很多样本
generate_rbox方法
idar.py::generate_rbox方法是最复杂也是最核心的代码,他负责,从4点的不规则四边形(4个点,8个值),rbox标注,变成6张图:score map(1),角度$\theta$(1),点到框的4个距离AABB(4),合计6个。
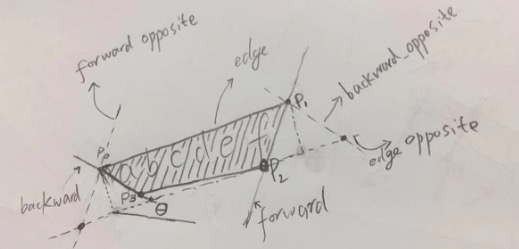
处理一个4边形的过程,如上图所示:
- 先确定直线$p_0p_1$,叫edge,$p_1p_2$,叫forward
- 然后看$p_3$和$p_2$离直线$p_0p_1$谁距离远,就选谁,做一条平行线(虚线),叫edge opposite
- 同理,看看$p_0$和$p_3$,谁离$p_1p_2$远,就通过谁,做一条平乡线(虚线),叫forword opposite
- 好,这样可以得到一个平行四边形
- 同理,还可以通过做$p_0p_3$的平行线,再得到一个平行四边形
- 然后挑一个面积最大的平行四边形出来
- 最后,做一个内接这个平行四边形的矩形出来
- 并,计算这个矩形的下边和x周的夹角
这里面涉及到一些数学公式,都不难,耐心的对着注释,自己动手画一画,都可以理解,如:
- 计算四边形的面积
- 如何做缩小四边形的计算(这个没看懂)
- 如何计算点到直线的距离
- 如何计算平行四边形的夹角(argtan)
- 如何计算两条直线的交点
需要额外提一句的是:fit_line函数
他返回的的是3个参数,实际返回的是一个直线的表示。我们都知道直线可以表示成$ax+by+c=0$,他返回的就是$[a,b,c]$,这个需要理解一下。
3、2 模型构建
https://github.com/zyh8306/EAST/blob/master/nets/model.py
里面会涉及到resnet50,其实我们也没有细读,大致看了一下,对着网上的resnet50的网络图对照了一下,差不多理解了,就pass了。
model
其中,model方法是核心:
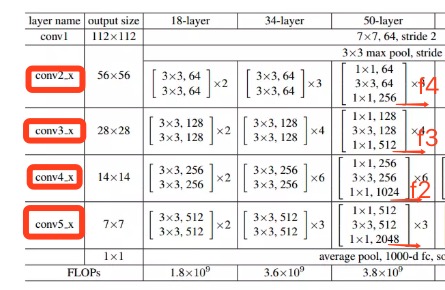
end_points['poolx'],这个就是resnet50中返回的feature map。我们一直脑海中有个问题,resnet50,有51层呢,到底哪些层吐出来的张量,喂给了我们的EAST的model,也就是,网络图中的$f1,f2,f3,f4$,其实,就是resnet中的图中的conv2,conv3,conv4,conv5他们的输出- 最下面的$f1$是原图大小的1/32;然后上卷积后和$f2$合体,大小是1/16;然后再上卷积后和$f3$合体,大小是1/8;然后上卷积后和$f1$合体,大小是1/4,对!这里有个细节,你得到feature map是原图的1/4,这个细节很重要
- 所以你得到的是的结果是 [W/4,H/4,512],那你如何从这个张量得到最后你想要的6张图的(我们都知道,EAST预测结果是6张图)
- 实际上,是通过6个核为[1x1],stride=1的卷积得到的,也就是右图中的蓝色框
loss
损失函数,和论文还是有些出入的
首先是,每个像素,是否是文本框内的点的分类的损失函数,按理说,应该是一个二分类,也就是二分类的交叉熵,但是,作者不知何故,改成了dice_coefficient,我也不知作者起这个名字表达啥意思,字面意思是,筛子相关系数。
这个函数的实现有点意思,作者说,没照着论文里的代码撸,而是换了个思路, 就是看 概率IoU = 交/并,交是所有的概率相加,并是所有的概率相加 这个loss在[-1,1]之间,好吧,就是想知道这个损失反向求导的函数是啥,呵呵
真心不知道作者是为何要这么干。
3、3 训练过程
https://github.com/zyh8306/EAST/blob/master/main/train.py
训练过程,没啥特殊的,就是常规的定义好各种summary scalar,准备好训练数据集、验证数据集,然后就可以session.run了
预测后的后处理
在训练的时候,需要验证,验证的时候,要把EAST预测的6张图,变成对应的所有的框,前面算法里面提到了,具体代码是如何实现的呢?
秘密就在eval.py::detect方法!
https://github.com/zyh8306/EAST/blob/master/main/eval.py
text_box_restored = restore_rectangle(xy_text[:,::-1]*4,# 为何要乘以4,上面解释了
这里说个细节,就是上面这句话,xy_text其实是每个点的坐标,为何要乘以4呢,原因就是,我们的网络得到的图,是原图的1/4,之前谈过这事,所以,这里要把这些坐标,都乘以4。
restore_rectangle_rbox方法
这个方法,是最核心的,里面的一些细节还暂时没搞清楚,大致理解,是做了一个旋转矩阵,然后把得到的根据每个点的4个距离和倾斜角度,得到这个点对应的框的4个点的值。
首先是构建了这样的数组p:
p = np.array([np.zeros(d_0.shape[0]),
-d_0[:, 0] - d_0[:, 2], # d维度是[h*w,4],d_0[:, 0]实际上是降维了[h*w],或者说[h*w,1],实际上得到是矩形的高
d_0[:, 1] + d_0[:, 3], # 矩形的长,维度是[h*w]
-d_0[:, 0] - d_0[:, 2], # 矩形的宽负数,维度是[h*w]
d_0[:, 1] + d_0[:, 3], # 矩形的长,维度是[h*w]
np.zeros(d_0.shape[0]),
np.zeros(d_0.shape[0]),
np.zeros(d_0.shape[0]),
d_0[:, 3],
-d_0[:, 2]])
观察这个数组,其实可以得到这样的一个数组$[0,-h,w,-h,w,0,0,0,left,]$,而你如果两两一对,进一步可以得到$[(0,h)(w,h),(w,0),(0,0)]$,这个是4个点的感觉,如果你画到坐标轴上,就是如下的一个图:
接下里的rotate_matrix_x,是$[cos\theta,sin\theta]$
旋转矩阵如下:
# [x'] [cos,-sin,0] [x]
# [y'] = [sin, cos,0] * [y]
# [1 ] [0 , ,1] [1]
也就是,$x’=x*cos\theta - y*sin\theta$,$y’=x*sin\theta + y*cos\theta$。
后续还要经过一个C语言写的lanms的,最终过滤出我们想要的框来,这个就更没有去细看了,感兴趣的同学可以深入去读一读。
验证
我们给增加了一个validate过程,之前的argman的代码是没有的,其中,我们用得到的框,传入evaluator.evaluate方法,这个方法实际上基于ICDAR2013的官方提供的评测方法[DetEval],参考。代码也是从官方的代码迁移过来的。
ICDAR2013则使用了新evaluation方法:DetEval,也就是十几年前Wolf提出的方法。“新方法”同时考虑了一对一,一对多,多对一的情况, 但不能处理多对多的情况。 (作者说,实验结果表示在文本检测里这种情况出现的不多。)
参考
- 七月在线有个不错的OCR课程,里面的好未来的杨老师讲了EAST,不错
- Argman大神的Github repo,我们的代码就是fork于他
- https://cloud.tencent.com/developer/article/1329171
- https://zhuanlan.zhihu.com/p/37504120
- 讲AdvancedEAST的