
概述
这篇综述讲的很好,知乎上有一个对这个摘要的介绍。里面的几个时间线的图很清晰说明了人脸的重要几方面的演变和进步:
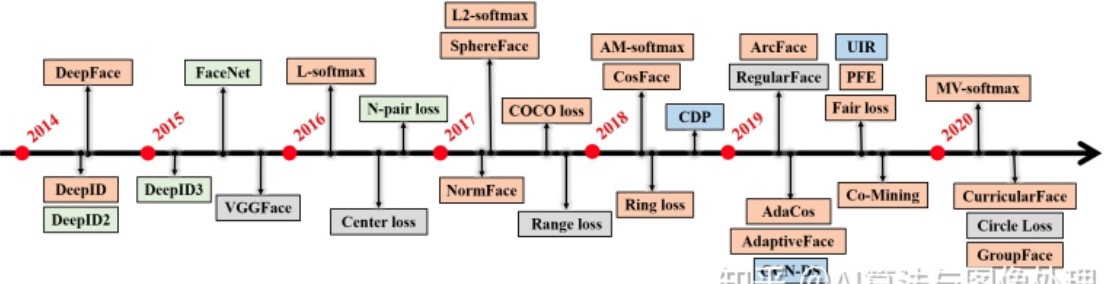
这个是人脸特征抽取的发展历程:
除了特征抽取,人脸还有很多其他方面,比如人脸检测、人脸对齐(人脸预处理)等。
我们在换个角度,我们来理解人脸的业务场景,可能更好理解:
1、人脸比对:我有张人脸,你那拿来一个人脸,问我这俩人脸是不是一个人
2、人脸检索:我拿来一张来,你去人脸库里,去帮我把这个人脸给检索出来
3、人脸关键点检测:把人脸的关键点(眼睛、鼻子、嘴巴等)给我标注出来
人脸比对,关键点是如何把人脸的特征有效的表达出来,另外用什么距离函数,可以算出两个脸是不是同一个人的脸。
人脸检索,核心点就是建立一个向量库,把人脸特征抽取后的,可能是个128维、也可能是512维的向量,存入到一个数据库中, 然后这个数据库还应该有个高效的索引方法,可以高效地计算出相似度的top10之类的。
人脸关键点检测,更像是一个目标检测,直接找到一个点,来确定这个点就是对应的嘴角啊、眼睛啥的。
我们业务上,最关心的是人脸比对,我们这篇文章也主要关注这点,人脸检索、关键点检测,我们就不深入研究了。
啰嗦几句,
我开始接触人脸识别的时候,脑子里就有一些问题,后来才一一解决:
人脸对比,经过一个神经网络,得到一个向量,然后呢?怎么训练呢?人脸数据的label是啥样?
后来,研究了一圈后,大概就明白了,这里直接讲出来,让跟我有同样困惑的同学快速理解:
人脸识别,本质上是要得到一张人脸的特征,这个特征是通过一个网络train出来,怎么train, 实际上大家都用的是常用的backbone,比如resnet,核心是后面接上一个loss,这个loss很关键。 这个loss是2部分组成:一个就是分类的交叉熵,让每个人的脸都尽量分开;二一个,是一个聚类损失,让每个人的特征尽量分开。
啊,你可能问,人脸怎么分类?每个人一类?对!答对了。就是这么变态。但是世界上有70亿+人呢?怎么办?不可能拿所有人的脸来训练啊?
不不不!
我们目的不是分出世界上每个人,而是要train出一个网络,有效的表达一个人脸的向量表达。 啥意思?就是一个人脸如果被有效表达出来之后,在用这个表达向量去做相似度,按照一个阈值,就可以算出是不是一个人了。 一般的数据集都提供上万个人,用这1万个人,train出这个网络来就达到目的了。 所以,每个数据集不同,网络的分类数也就会不同。
而,让不同人的特征尽量距离分开,类似于聚类分开,这个事这里就详细赘述了,后面会专业讨论。
有了上述的描述,你应该对人脸识别有了快速的理解了,我开始困惑的事儿就这点事,搞清楚,剩下的就是细节了。
这篇文章里,我不太想按照一般的人脸识别文章去写,那些基础知识没必要在赘述,无数文章都说的很清楚了。 我只想把我的困惑和我的理解过程,我的深入思考,写出来。
人脸检测
人脸检测,其实可以采用任何的目标检测网络,比如mask-rcnn、yolo等,这里,我们把目光投向人脸这个领域, 比较有名的有MTCNN,RetinaFace等。
大家公认的不错的是RetinaFace,它是2019.5时候提出的。 我们其实也没有去考察太多的其他的检测模型,只是深入研究后,使用它作为我们人脸检测的主力模型。
RetinaFace
先整体说一下:
- 用了FPN来抽取特征
- 同时用5点landmark对齐人脸
损失函数
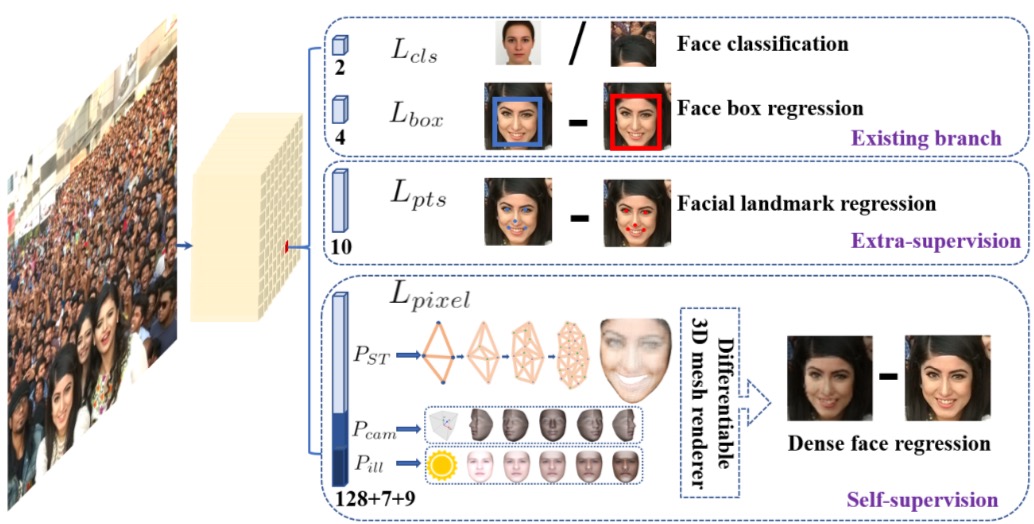
最后一项是点云的,我们用不到,也没做深入研究,只说说前3项:
- $L_{cls}$:是否是人脸的分类损失函数,2分类,交叉熵
- $L_{box}$:${t_x,t_y,t_w,t_h}人脸框的坐标的均方误差$
- $L_{pts}$:5个对齐用的lardmark点的均方误差
另外,$\lambda_1,\lambda_2,\lambda_3$的值,论文建议的是0.25,0.1,0.01,因为我们不太关心点云的预测,所以我们把$\lambda_3$设成0。
模型细节
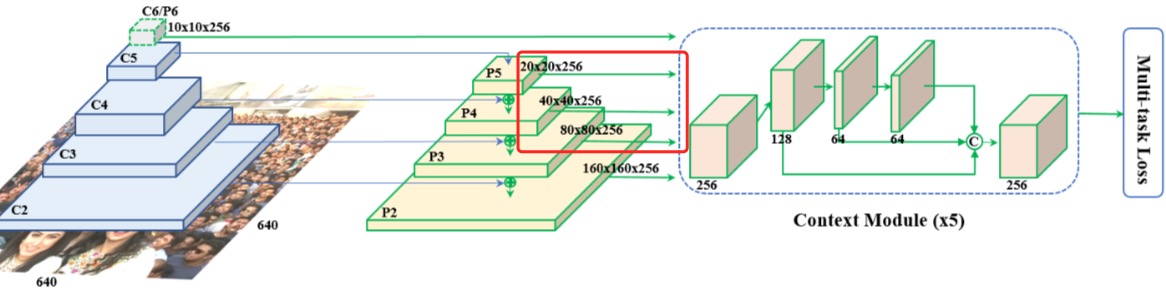
1、实现一个FPN
用backbone抽出5层来,通道channel都是256,但是尺寸不同,分别是:
输入是[640,640],5层分别是:
- [10,10,256],1/64
- [20,20,256],1/32
- [40,40,256],1/16
- [80,80,256],1/8
- [160,160,256],1/4
不过,我看到代码中,往往不用那么多层,只用3层就够了,
- [20,20,256],1/32
- [40,40,256],1/16
- [80,80,256],1/8
代码:
fpn = self.fpn(out)
feature1 = self.ssh1(fpn[0]) # M:[H/8,W/8,64], R[H/8,W/8,256]
feature2 = self.ssh2(fpn[1]) # M:[H/16,W/16,64],R[H/16,W/16,256]
feature3 = self.ssh3(fpn[2]) # M:[H/32,W/32,64],R[H/32,W/32,256]
2、Context Module
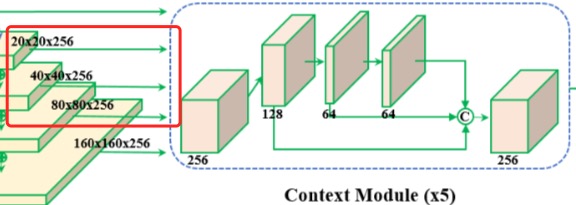
从FPN过来的5个张量(代码中实现的是3个张量), 经过这个
we also replace all 3 × 3 convolution layers within the lateral connections and context modules by the deformable convolution network (DCN) [9, 74], which fur- ther strengthens the non-rigid context modelling capacity.
貌似,我fork的代码,也没有是实现变形卷积deformable convolution。
这里多说一下变形卷积,其实是学一个2个核,举个例子吧,我有个3x3的卷积核,除了学习这个3x3的卷积核外,还要学习一个3x3x2的偏移量的参数,最后的2含义是学习偏移offset的x和y值。学习出来后,用这个x、y,先算出3x3里每个点应该偏移的位置(如果出现小数,就用双线性差值来算原图上的像素的值),现在你的卷积核(9个)有,变形到原图上的位置的像素值(9个)有(小数位置已经差值了),然后就对应位置做卷积即可。
FDDB
FDDB(缩写Face Detection Data Set and Benchmark),是一个比较有名的针对人脸识别算法的评测方法与标准。 一共包含了2845张图片,包含彩色以及灰度图,其中的人脸总数达到5171个。包含遮挡、大角度、低分辨率、模糊,使用椭圆标注人脸,灰度和彩色都有。
椭圆标注:

人脸就可以用5个变量来表征:
- ra:椭圆长轴半径
- rb:椭圆短轴半径
- theta:椭圆长轴偏转角度
- cx:椭圆圆心x坐标
- cy:椭圆圆心y坐标
交并比:
FDDB使用交并比来表示标注框和检测框的匹配程度:交并比 = 两个框的重叠面积 / 两个框的联合面积
检测框和标注框对应问题,等效于一个二分图(bipartite graph)的最大匹配(maximum matching),使用匈牙利算法(Hungarian algorithm)求解。 就是找到检测框和标注框的最优匹配。

常见的人脸检测算法
- Ultra-Light-Fast-Generic-Face-Detector-1MB,参量数:1.04~1.1MB,代码
- LFFD:A Light and Fast Face Detector for Edge Devices,参数量:6.1 M,一筐款通吃大小目标、支持各种设备的人脸检测器,论文,代码。
- libfacedetection,参数量:3.34M,一个用于在图像中进行人脸检测的开源库。人脸检测速度可以达到1000FPS。代码
- CenterFace,参数量:7.3MB,改进版仅为2.3M,CenterFace是一种用于边缘设备的实用的无锚人脸检测和对齐算法。代码
- DBFace,参数量:7.03MB,DBFace是一个Anchor Free的网络结构。代码
- BlazeFace,一款专为移动GPU推理量身定制的轻量级且性能卓越的人脸检测器。论文,代码
- RetinaFace,参数量:1.68M,代码
- MTCNN,论文,代码
- SSDFace,论文
- facebox,论文
- yoloface,讲yolo检测应用于人脸,代码
参考
人脸特征抽取
人脸特征抽取非常非常关键,可以说是人脸识别这个大领域里最核心的环节。
前面其实已经提到了,就是用一个经典的backbone(如resnet)来抽取人脸特征,如果直接用交叉熵, 去训练数据集中的1万个人(比如Webface中提供11000个人的照片),从而得到一个网络,用来抽取未来别的人的特征,这个思路没啥问题。
但是,问题是,你能train出来么?
假设你能train出来?
那,我现在拿一个训练集之外的一个人脸,经过这个网络计算后,得到的这个新人的人脸表示向量,可能和1万个人的人脸表示距离很近, 然后我再拿一堆的训练集之外的新人的脸,他们是不是能和训练集中的1万个人分开,他们之间是不是能分开?不一定吧。 如果不能分开,你怎么做后续的人脸比对呢。
所以,这就要求,每个人的人脸表示,都要尽量的分开。在训练集中的1万个人的人脸如果能尽量分开,把这个作为一种损失函数去逼迫 网络尽量分开人脸表示,这个网络学会了,“尽量分开”的能力,那么再来新脸,也会尽量分开了。
这就引出一系列,帮助把一个人的人脸表示和别的人的人脸表示分开的loss函数。
来,再祭出这张图,也就是这些年,前赴后继大神们的为了分开人脸表示做出的努力:
我们说他们发展的这个脉络吧:
- centerloss
- tripleloss
- A-softmax(SphereFace)
- L-softmax
- CosFace
- AM-softmax
- ArcFace
我勒个去,这么多啊,对滴。这里,强力安利一下Mengcius的人脸识别合集, 讲的实在是太好了,我就是跟着他的系列文章学习下来的。另外还有,YaqiYU的人脸的loss(上,下),讲的也很不错。
别急,我们挨个说:
softmax
哎~,你怎么把softmax先贴上来了。
对!分开人脸,首先就得用softmax,用交叉熵,可是,光用softmax是分不开那么多人的啊,所以,上来,我们先说说softmax的问题。
下面的这些softmax的不足,都参考自人脸识别损失函数综述。
$L=-\frac{1}{N} \sum_{i=1}^{N} \log \frac{e^{W_{y_{i}}^{T} x_{i}+b_{y_{i}}}}{\sum_{j=1}^{n} e^{W_{j}^{T} x_{i}+b_{j}}}$
softmax训练的时候收敛得很快,但是精确度一般达到0.9左右就不会再上升了
softmax不能像metric learning一样显式的优化类间和类内距离,所以性能不会特别好
Metric Learning的概念,它是根据不同的任务来自主学习出针对某个特定任务的度量距离函数。通过计算两张图片之间的相似度,使得输入图片被归入到相似度大的图片类别中去。通常的目标是使同类样本之间的距离尽可能缩小,不同类样本之间的距离尽可能放大
softmax不具备metric learning的特性,没法压缩同一类别
center loss用于压缩同一类别,为每一个类别提供一个类别中心,最小化每个样本与该中心的距离
解释一下,就是softmax虽然可以把类别分开,但是,没法衡量不同类别之间距离,这样就会导致再来一个我训练集之外的人脸, 可能会被划到一个我已有的训练集中的人脸类别中,这个是问题所在。
那想办法吧,
Centerloss
centerloss特朴素,特像聚类。既然你分不开,那,我们就让每个人脸的类别尽量“聚集”,方法就是让每个类别都和它的中心尽量“近”!
这个就避免了softmax的不具备metric learning的特点啦!
新的损失函数:
$L=-\frac{1}{N} \sum_{i=1}^{N} \log \frac{e^{W_{y_{i}}^{T} x_{i}+b_{y_{i}}}}{\sum_{j=1}^{n} e^{W_{j}^{T} x_{i}+b_{j}}}+\frac{\lambda}{2} \sum_{i=1}^{N}\left|x_{i}-c_{y i}\right|^{2}$
的后半部分,
$\frac{\lambda}{2} \sum_{i=1}^{N}\left|x_{i}-c_{y i}\right|^{2}$
就是这个centerloss的核心!
$c_{yi}$,是要动态算的,你每次train一个新的人脸,就要用它去修正原有的这个类别的$c_{yi}$,这个细节很重要。
不停的训练,让新来的训练样本,尽量靠近这个中心,这个中心也在不断修正(实现时候只能靠移动平均方法更新)。
TrippleLoss
各个样本都向中心聚了,挺好的,网络计算完的特征,都向这个中心聚了,很好!
可是,这些中心都很近,不就也不好了嘛,对,这就是tripple loss的朴素思想的来源。
$\left|x_{i}^{a}-x_{i}^{p}\right|^{2} + m < \left|x_{i}^{a}-x_{i}^{n}\right|^{2}$
$x_{i}^{a}$是被训练的图片,$x_{i}^{p}$是跟他一样的类别(正类Positive),$x_{i}^{n}$是跟他不一样的类别(负类Negtive)。 他们之间的关系是,和异族的距离,至少要比同族的距离,大m。
不过,tripple loss不好训练。
缺点是过于关注局部,导致难以训练且收敛时间长
还有人说是因为,正负不均衡,正例太少,负例太多啥的。不过,我也没去实践,就不多言了。
虽然有了,centerloss,trippleloss,但是,还是有大神们继续探索,就有了L-Softmax。
L-Softmax
L-softmax,2016 ,Weiyang Liu@北大
之前的centerloss、tripple loss,都用的是欧氏距离,接下来的大神们,开始尝试余弦距离,这也就是A-softmax的由来。
这个余弦距离怎么来的呢?我来娓娓道来:
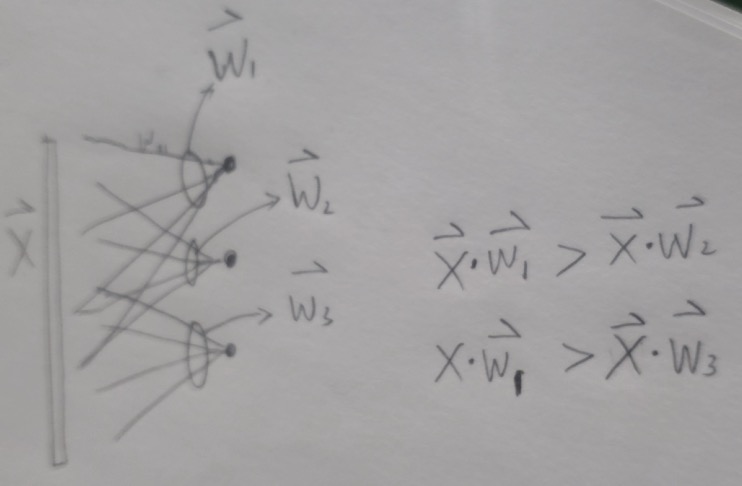
看这种图,我们的特征抽取后,最后经过这个全连接,权重W是[隐含层 x 人脸类别], 每个人脸类别,就对着一个W向量$\overrightarrow{W}$,比如W的维度是[512,10000], 那么$\overrightarrow{W}$的维度就是512,有10000个这样的$\overrightarrow{W}$: $\overrightarrow{W_1},\overrightarrow{W_2},\overrightarrow{W_3},…$
为了分类分开,一定是一个$\overrightarrow{W}$,比如$\overrightarrow{W_1}$, $\overrightarrow{W_1} \cdot x$ 比别的$\overrightarrow{W_2},$\overrightarrow{W_3}$,…和x内积值都要大,(softmax只是用指数放大了这个差异而已)。
好,这个$\overrightarrow{W_1} \cdot x$,可以表示成,$|\overrightarrow{W_1}| * |x| * cos(\theta_1)$(嘿嘿,余弦出现了)
以下是参考:人脸识别损失函数综述中的解释:
原始的Softmax的目的是使得 $W_1^Tx > W_2^Tx$, 这个意思是softmax公式中, 那个$e^{W^T x_i}$上的指数项目标类别肯定是最大(softmax只是放大了它而已), 所以,做个变形,就成了,$|W_1|\cdot |x|\cdot cos(\theta_1) > |W_2|\cdot |x|\cdot cos(\theta_2)$, 这个是可以理解的,顺理成章的。
然后在这个基础之上,在把$cos(\theta)$做一个变形,
变成了
\[\varphi(\theta)=\begin{cases} cos(m\theta),0 ≤ \theta≤\frac{\pi}{m} \\ D(\theta), \frac{\pi}{m}≤\theta≤ \pi\\ \end{cases}\]乘以m(m≥1),实际上是加大了夹角$\theta$,你想啊,本来W和x有个夹角$\theta$,结果你现在乘以一个m,让损失其实是变得更大了,所以对这个$\theta$的要求,得更小才可以。
我觉得,从理解上,算W和x的夹角$\theta$,容易让人迷惑,不是应该只算x们之间的距离啥的么?W是个什么鬼?!我觉得,可以这样理解:你把W当做一个中介,x1和W1算,夹角尽量小,但是x2和其他的跟x1不是一类的向量来说,跟W2算夹角都很大,这样,就相当于变相的把非我族类给推远了,但是,如果某个xi和x1很像,它应该和W1的距离也应该很近才对。你看!这样不就是达到了同类往一起聚,不同类往不同的方向聚么。
A-Softmax
SphereFace/A-Softmax 2017 Weiyang Liu@佐治亚
关于SphpereFace,YaqiYU的人脸的loss(人脸的loss)讲的很好,摘抄和注释一下:
Softmax鼓励不同类别的特征分开,但并不鼓励特征分离很多
Softmax并不要求类内紧凑和类间分离,这一点非常不适合人脸识别任务,因为训练集的1W人数,相对测试集整个世界70亿人类来说,非常微不足道,而我们不可能拿到所有人的训练样本,更过分的是,一般我们还要求训练集和测试集不重叠,需要改造Softmax,除了保证可分性外,还要做到特征向量类内尽可能紧凑,类间尽可能分离。
Mengcius哥们讲也好,这里摘抄和注释一下:
SphereFace(超球面)是佐治亚理工学院Weiyang Liu等在CVPR2017.04发表
SphereFace是在softmax的基础上将权重归一化,即使得 $|W_i|=1, bias=0$,使得预测仅取决于W和x之间的角度。
我不太理解?$|W_i|=1$,怎么个法?!W不是我要去求的东西么?加了这个约束,我还怎么训练呢? 后来,想明白这事了,它只是个约束,不影响你训练啊。
为了实现角度决策边界,最终FC层的权重实际上是无用的
靠,这个说法够让我毁三观的
在每次迭代中权重归一化为1
噢,终于理解怎么实现了!
我理解,$|W_i|=1$,是A-softmax的最大改进,只关注角度了。
上面是对Mengcius小哥的理解,下面我说说我的理解:
arcface
说说arcface吧,这个是我最主要化精力研究和使用的,arcface应该说是吸收了前面这个几个x-softmax的基础之上,做的最好的一个了。
这个是我实现的一个版本, 是fork自一个网友的github,在开发过工程中,随着对代码的理解,我对arcface也有了更深入和细致的理解。有必要花最大篇幅来说说它。
再论softmax
前面已经提到过softmax和其问题了,这里再唠叨几句,为何呢?因为让自己头脑更清晰,更容易一步步的深入arcface的细节:
softmax是什么? 这篇里,认知更清晰,softmax不涉及到任何参数,它就是个放大器。看这张图,理解更深入。
这个是: $\frac{e^{x_i}}{\sum_{j=1}^{n} e^{x_i}}$,$x_i$是一个维度,如$[x_1,x_2,x_3]$,
比如一个向量,argmax,[3,1,-3],经过softmax,是[0.88,0.12,0],差距被放大了。
但是,往往前面都会再接一个网络:$Y = X*W + b$
比如X维度是128维,W维度是[128,10],现在的$x_i$实际上是$y_i$,然后再softmax,所以softmax只是在最后一个阶段帮着”放大“一下而已。
本质上,还是要靠前面的参数W,毕竟我们是为了要train这些Weight的,softmax只是在为了最后推波助澜而已:
$\frac{e^{W_{y_{i}}^{T} x_{i}+b_{y_{i}}}}{\sum_{j=1}^{n} e^{W_{j}^{T} x_{i}+b_{j}}}$。
arcface loss
softmax的虽然可以做分类,但是类别多了,就容易出现在高维空间中的边界区分不开的情况,一片一片的感觉, 我们形象地想,能不能让不同分类的表示向量,都能聚簇到一起,这样彼此间就可以分的很开了。 这个就是前面l-softmax、a-softmax等,包括arcface,通俗易懂的想法。
那问题是,如何才能达到这个目标呢?
在softmax中,我们观察softmax上的分子上面的项,$W_{y_{i}} x + b_{y_{i}}$,这里需要详细说一下,$x$是512维(假设的,是从backbone抽取之后的)。 这里的$W_{y_{i}}$是一个512维度的向量(这个是$W$矩阵[512,10000]中的一列)。这俩相乘,得到的是一个数(标量),这个标量, 是在得到的10000分类概率向量中的$y_i$分类上的概率(当然还得除以分母)。 你用$x * W_{y_0}$得到0分类的值,然后用$x * W_{y_1}$得到1分类的值,。。。,一共有10000个$W_{y_i}$, 得到了这个$x$对应的每个分类上的概率值,他们拼起来,是一个10000维度的概率向量。
接着说,
现在$W_{y_{i}} x + b_{y_{i}}$,这个你就可以理解成要变成概率的人,我们把这个玩意,做几个变形:
- 先让$b_{y_{i}}=0$,b不要啦
- 再让$W_{y_{i}} \cdot x$ => $|W_{y_{i}}| * |x| * cos(\theta)$
- 然后再让$|W_{y_{i}}| = 1, |x|= 1 $
- 再做个半径缩放,本来半径现在都是1了,是不是感觉太挤?然后给了一个s,变成 $s * cos(\theta)$
- 最后,再加一个惩罚项$m$,加到$\theta$上,惩罚啥?我理解,就是你想着离$W_{y_i}$更近,但我偏不让你更近,给你加个$m$,逼着你更努力!
最后,这个softmax就被改造成了这个样子:
$L_{3}=-\frac{1}{N} \sum_{i=1}^{N} \log \frac{e^{s\left(\cos \left(\theta_{y_{i}}+m\right)\right)}}{e^{s\left(\cos \left(\theta_{y_{i}}+m\right)\right)}+\sum_{j=1, j \neq y_{i}}^{n} e^{s \cos \theta_{j}}}$
这里,啰嗦几句再:
这还是个softmax,虽然给做了各种的变形、约束和简化,丫还是个softmax,本质上。他还是要让属于$y_i$那类的那个概率值,算出来,是最大的。 这样去逼着$W$们,不断地梯度下降,去达到这个目标。 但是,这个所以为“值”,也就是要被softmax放大的值,也就是要努力做到最大的值,变成了一个$cos$值,注意不是$\theta$,它也要最大。 $cos(\theta)$函数是一个递减函数,所以,它最大,就要求$\theta$最小。 $\theta$是啥来着? $\theta$是$x$(backbone萃取出的feature,512维)和这个类别对应的$W_{y_i}$(W矩阵[512,10000]中的一类,即512维的向量),这两个向量的夹角。 现在,我们就是要我们的同一个人的萃取出来的$x$,都尽量向这个人的对应的$W_{我}$,尽量的靠近、靠近、靠近(也就是夹角$\theta$尽量小)!这就是这个loss的本质!
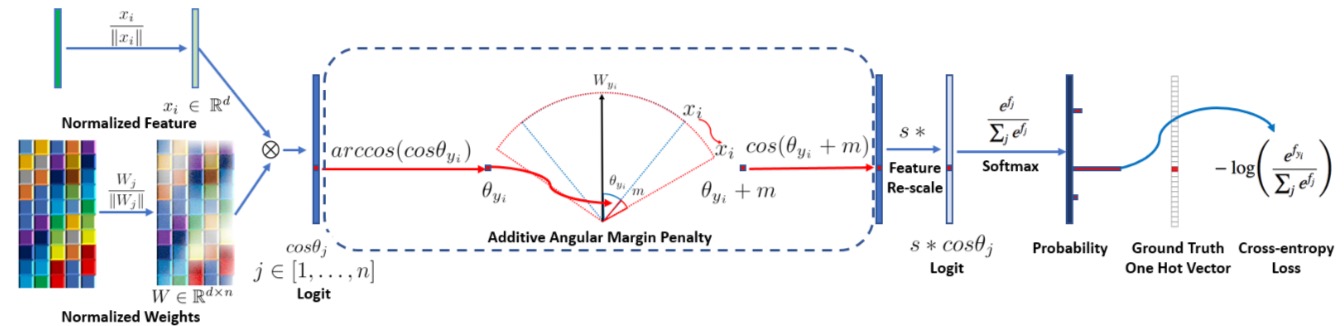
不得不说,这图画的很好,很形象!
再说说代码
实现代码
原理懂了,实现上,相对也比较容易了。但是还是需要一些细节需要解释。
要实现$cos(\theta_{y_i}+m)$,需要把这个式子“积化和差”,所以要求出sin啥的,这个细节如果没搞清楚,会晕。 另外,这个所谓的metrics,要计算的不是loss,而是给loss准备的softmax的分子,也就是e的指数的值,也就是$s*cos(\theta_{y_i}+m)$。 这个得到的是一个cos值,但是确切的说不是一个cos值,而是10000个,所以有必要认真分析一下它的输入和输出:
输入:input,是一个512维度的向量;
输出:是一个s缩放后的$\overrightarrow{cos}$值,是一个10000维度的,也就是有个10000个cos值,为何?
是因为,你这个input,即$x$,经过这个arcface的子网络后,得到一个$\overrightarrow{cos}$向量(10000维), 只有$y_i$那个维度对应的cos值(这个时候是标量),应该最大,而其他的9999个维度上的cos值(标量)应该相对比较小, 这样,经过softmax这个放大器后就更明显了,然后,再交叉熵,刺激损失函数梯度下降去吧。
代码:
def forward(self, input, label):
"""
@param input: 512维向量
@param label:
其实就是在实现 softmax中的子项 exp( s * cos(θ + m) ),
但是因为cos里面是个和:θ + m
所以要和差化积,就得分解成:
- exp( s * cos(θ + m) )
- cos(θ + m) = cos(θ) * cos(m) - sin(θ) * sin(m) = cos_θ_m(程序中的中间变量) # 和差化积
- sin(θ) = sqrt( 1 - cos(θ)^2 )
- cos(θ) = X*W/|X|*|W|
s和m是超参: s - 分类的半径;m - 惩罚因子
这个module得到了啥?得到了一个可以做softmax的时候,归一化的余弦最大化的向量
"""
logger.debug("[网络输出]arcface的loss的输入x:%r", input.shape)
# --------------------------- cos(θ) & phi(θ) ---------------------------
"""
>>> F.normalize(torch.Tensor([[1,1],
[2,2]]))
tensor([[0.7071, 0.7071],
[0.7071, 0.7071]])
这里有点晕,需要解释一下,cosθ = x.W/|x|*|W|,
注意,x.W表示点乘,而|x|*|W|是一个标量间的相乘,所以cosθ是一个数(标量)
可是,你如果看下面这个式子`cosine = F.linear(F.normalize(input), F.normalize(self.weight))`,
你会发现,其结果是10000(人脸类别数),为何呢?cosθ不应该是个标量?为何现在成了10000的矢量了呢?
思考后,我终于理解了,注意,这里的x是小写,而W是大写的,这个细节很重要,
x是[Batch,512],而W是[512,10000],
而其实,我们真正要算的是一个512维度的x和一个10000维度的W_i,他们cosθ = x.W_i/|x|*|W_i|,这个确实是一个标量。
但是,我们有10000个这样的W_i,所以,我们确实得到了10000个这样的cosθ,明白了把!
所以,这个代码就是实现了这个逻辑。没问题。
再多说一句,arcface,就是要算出10000个θ,这1万个θ,接下来
"""
cosine = F.linear(F.normalize(input), F.normalize(self.weight)) # |x| * |w|
logger.debug("[网络输出]cos:%r", cosine.shape)
# clamp,min~max间,都夹到范围内 : https://blog.csdn.net/weixin_40522801/article/details/107904282
sine = torch.sqrt((1.0 - torch.pow(cosine, 2)).clamp(0,1))
logger.debug("[网络输出]sin:%r", sine.shape)
# 和差化积,cos(θ + m) = cos(θ) * cos(m) - sin(θ) * sin(m)
cos_θ_m = cosine * self.cos_m - sine * self.sin_m
logger.debug("[网络输出]cos_θ_m:%r", cos_θ_m.shape)
if self.easy_margin:
cos_θ_m = torch.where(cosine > 0, cos_θ_m, cosine)
else:
# th = cos(π - m) ,mm = sin(π - m) * m
cos_θ_m = torch.where(cosine > self.th, cos_θ_m, cosine - self.mm)
# --------------------------- convert label to one-hot ---------------------------
one_hot = torch.zeros(cosine.size(), device=self.device)
logger.debug("[网络输出]one_hot:%r", one_hot.shape)
# input.scatter_(dim, index, src):从【src源数据】中获取的数据,按照【dim指定的维度】和【index指定的位置】,替换input中的数据。
one_hot.scatter_(dim=1, index=label.view(-1, 1).long(), src=1)
# -------------torch.where(out_i = {x_i if condition_i else y_i) -------------
# 这步是在干嘛?是在算arcloss损失函数(论文2.1节的L3)的分母,
# 标签对的那个分类y_i项是s*cos(θ_yi + m),而其他分类则为s*cos(θ_yj), 其中j!=i,
# 所以这个'骚操作'是为了干这件事:
output = (one_hot * cos_θ_m) + ((1.0 - one_hot) * cosine)
logger.debug("[网络输出]output:%r", output.shape)
output *= self.s
logger.debug("[网络输出]arcface的loss最终结果:%r", output.shape)
# 输出是啥??? => torch.Size([10, 10178]
# 自问自答:输出是softmax之前的那个向量,注意,softmax只是个放大器,
# 我们就是在准备这个放大器的输入的那个向量,是10178维度的,[cosθ_0,cosθ_1,...,cos(θ_{i-1}),cos(θ_i+m),cos(θ_{i+1}),...]
# 只有这项是特殊的,θ_i多加了m,其他都没有---> ~~~~~~~~~~
# 不是概率,概率是softmax之后才是概率
return output
输出:
DEBUG: [网络输出]arcface的loss的输入x:torch.Size([10, 2])
DEBUG: [网络输出]cos:torch.Size([10, 10178])
DEBUG: [网络输出]sin:torch.Size([10, 10178])
DEBUG: [网络输出]cos_θ_m:torch.Size([10, 10178])
DEBUG: [网络输出]one_hot:torch.Size([10, 10178])
DEBUG: [网络输出]output:torch.Size([10, 10178])
DEBUG: [网络输出]arcface的loss最终结果:torch.Size([10, 10178])
看到了吧,就是10178个cos值(这里我用的数据集是10178个分类,我文章中简单化为了10000种),前面的是10是batch,可以忽略。
数据集
人脸训练用的数据,可以参考这个列表,比较全!
人脸识别数据集
WebFace 10k+人,约500K张图片 非限制场景,图像250x250
FaceScrub 530人,约100k张图片 非限制场景
YouTubeFace 1,595个人 3,425段视频 非限制场景、视频
LFW 5k+人脸,超过10K张图片 标准的人脸识别数据集,图像250x250
MultiPIE 337个人的不同姿态、表情、光照的人脸图像,共750k+人脸图像 限制场景人脸识别
MegaFace 690k不同的人的1000k人脸图像 新的人脸识别评测集合
IJB-A 人脸识别,人脸检测
CAS-PEAL 1040个人的30k+张人脸图像,主要包含姿态、表情、光照变化 限制场景下人脸识别
Pubfig 200个人的58k+人脸图像 非限制场景下的人脸识别
CeleBrayA 200k张人脸图像40多种人脸属性,图像178x218
人脸检测数据集
FDDB 2845张图片中的5171张脸 标准人脸检测评测集 链接
IJB-A 人脸识别,人脸检测 链接
Caltech10k WebFaces 10k+人脸,提供双眼和嘴巴的坐标位置 人脸点检测 链接
参考
- 人脸识别技术全面总结:从传统方法到深度学习
- 2020人脸识别最新进展综述,参考文献近400篇
- 入门经典综述!深度人脸识别算法串讲
- 2020最强六大开源轻量级人脸检测项目分析,
- AIZOO开源人脸口罩检测数据+模型+代码
- 北科大研究生的github总结,很不错,很多干活,各方面的
- Mengcius的人脸识别合集
- 人脸的loss(上,下)
- 盘点在人脸识别领域现今主流的loss(1,2)